1、并发编程
为什么要使用多线程?
串行、并行和并发有什么区别?
串行:指多个任务按顺序依次完成。此时反而使用单线程效果更好,避免了线程的切换。
并发(concurrency):指两个或多个事件在同一个时间段内发生。即在一段时间内,有多条指令在单个CPU上快速轮换、交替执行,使得在宏观上具有多个进程同时执行的效果。(微观上分时交替执行,宏观上同时进行)
比如:
小渣有五个女朋友,在某一天的上午7点到12点需要与五个女朋友约会,在7-8点他与女友A约会,8-9点他与女友B约会,9-10点他与女友C约会,10-11点他与女友D约会,11-12点他与女友E约会,他在一上午与5个女朋友约会了,在宏观上他就是在8-12点这段时间内与五个女朋友一起约会了。
并行(parallel):指两个或多个事件在同一时刻发生(同时发生)。指在同一时刻,有多条指令在多个CPU上同时执行。
比如:
小渣有五个女朋友,在某一天的上午7点到12点需要与五个女朋友约会,意思就是在7-12点这段时间(假设这是一个时刻)内要与五个女朋友一起约会,这就叫并行。(但是这在现实生活中肯定是不肯的,除非有五个小渣)
进程、线程、管程、协程区别?
进程(Process)
进程是操作系统调度和分配资源的最小单位。每个进程都有自己的内存空间、文件描述符、堆栈等资源。如:运行中的 QQ,运行中的网易音乐播放器。
进程的特点
- 独立性:进程之间是独立的,互不干扰。一个进程的崩溃不会影响其他进程。
- 资源丰富:每个进程拥有独立的资源,包括内存、文件句柄等。
- 开销大:创建和销毁进程的开销较大,进程间通信(IPC)也相对复杂。
- 上下文切换:进程的上下文切换开销较大,因为需要切换内存空间和资源。
使用场景
- 适用于需要强隔离和独立资源的场景,如独立的服务、应用程序等
线程 (Thread)
线程是进程内的执行单元,一个进程可以包含多个线程。线程共享进程的资源(如内存空间、文件描述符)。一个进程中至少有一个线程。
线程的特点
- 共享资源:同一进程内的线程共享内存和资源,通信方便。
- 轻量级:与进程相比,线程更加”轻量级“,线程的创建和销毁开销较小,上下文切换较快。
- 并发执行:多线程可以并发执行,提高程序的响应速度和资源利用率。
- 同步问题:由于共享资源,线程间需要同步机制(如锁)来避免资源竞争和数据不一致。
使用场景
- 适用于需要并发执行的任务,如多任务处理、并行计算等。
注意:
- 不同的进程之间是不共享内存的。
- 进程之间的数据交换和通信的成本很高。
管程 (Monitor)
管程是一种高级的同步机制,用于管理共享资源的并发访问。它将共享资源和访问资源的代码封装在一起,通过条件变量和互斥锁来实现同步。
管程特点
- 封装性:将共享资源和同步代码封装在一起,提供更高层次的抽象。
- 互斥访问:通过互斥锁确保同一时刻只有一个线程可以访问共享资源。
- 条件同步:使用条件变量来协调线程间的执行顺序。
使用场景
- 适用于需要对共享资源进行复杂同步操作的场景,如操作系统内核、并发数据结构等。
协程 (Coroutine)
协程是一种比线程更轻量级的并发执行单元。协程由程序自身调度,而不是由操作系统内核调度。协程可以在执行过程中主动让出控制权,以便其他协程运行。
协程特点
- 轻量级:协程的创建和切换开销极小,通常在用户态完成。
- 主动让出:协程通过显式的调用(如yield)让出控制权,实现合作式多任务。
- 非抢占式:协程之间的切换是合作式的,不存在抢占问题。
- 栈独立:每个协程有自己的栈,避免了线程间共享栈带来的同步问题。
使用场景
- 适用于需要大量并发任务且切换频繁的场景,如高并发网络服务器、异步编程等。
虚拟线程 (Virtual Thread)
虚拟线程是一个新概念,特别是在 Java 的 Project Loom 中引入。虚拟线程是一种轻量级线程,由 JVM 管理,旨在简化并发编程并提高并发性能。
特点
- 轻量级:虚拟线程的创建和销毁开销极小,可以高效地管理数百万个线程。
- 自动管理:由 JVM 自动调度和管理,不需要开发者显式地管理线程池。
- 兼容性:与传统的 Java 线程 API 兼容,开发者可以用熟悉的线程模型编写高并发程序。
- 阻塞操作:虚拟线程可以在阻塞操作(如 I/O 操作)时高效地让出 CPU,而不会浪费资源。
使用场景
- 适用于高并发应用程序,如高性能服务器、Web 应用等。
用户线程与守护线程区别?
用户线程
用户线程是应用程序创建的普通线程,也称为非守护线程。当所有用户线程都结束时,Java 虚拟机 (JVM) 也会退出。
特点
生命周期:用户线程的生命周期由应用程序控制。只要有一个用户线程在运行,JVM 就会继续运行。
重要性:用户线程通常用于执行应用程序的主要任务,例如处理业务逻辑、执行计算等。
关闭 JVM:JVM 只有在所有用户线程都结束后才会退出,即使还有守护线程在运行。
使用场景
- 适用于需要执行重要任务且不能中途被终止的线程。例如:处理用户请求的线程,执行关键业务逻辑的线程
守护线程 (Daemon Thread)
守护线程是为其他线程提供服务和支持的线程。当所有非守护线程(用户线程)都结束时,JVM 会自动退出,即使守护线程还在运行。
特点
生命周期:守护线程的生命周期依赖于用户线程。当所有用户线程结束时,守护线程也会自动终止。
后台任务:守护线程通常用于执行后台任务,如垃圾回收、日志记录等。
低优先级:守护线程通常优先级较低,因为它们主要为用户线程提供支持。
使用场景
- 适用于执行后台任务或辅助任务的线程,这些任务不需要在 JVM 退出时完成。例如:JVM 的垃圾回收线程,日志记录线程,监控和统计线程
示例
public class ThreadExample {
public static void main(String[] args) {
Thread userThread = new Thread(() -> {
try {
Thread.sleep(5000);
System.out.println("User thread finished");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Thread daemonThread = new Thread(() -> {
while (true) {
try {
Thread.sleep(1000);
System.out.println("Daemon thread running");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
daemonThread.setDaemon(true);
userThread.start();
daemonThread.start();
System.out.println("Main thread finished");
}
}在这个例子中:
userThread是一个用户线程,它会运行 5 秒钟。daemonThread是一个守护线程,它会每秒钟打印一次消息。
当userThread结束后,JVM 会退出,即使daemonThread还在运行
线程的基本方法(Thread类的方法)
start()
start()方法用于启动线程。线程创建以后,并不会自动运行,需要我们调用start(),将线程的状态设为就绪状态,但不一定马上就被运行,得等到CPU分配时间片以后,才会运行
class MyThread extends Thread {
@Override
public void run() {
System.out.println("Thread is running");
}
}
public class Main {
public static void main(String[] args) {
MyThread t1 = new MyThread();
t1.start(); // 启动新线程
}
}注意:直接调用run()方法不会启动新线程,而是在当前线程中执行run()方法。
run()
run()方法包含线程执行的代码。它是Thread类和Runnable接口的核心方法
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("Thread is running");
}
}
public class Main {
public static void main(String[] args) {
Thread t1 = new Thread(new MyRunnable());
t1.start(); // 启动新线程,实际调用的仍是 run() 方法
}
}sleep(long millis)
sleep(long millis)方法使当前线程休眠指定的毫秒数。它会抛出InterruptedException,因此需要处理该异常。
try {
System.out.println("Thread is sleeping");
Thread.sleep(1000); // 休眠1秒
System.out.println("Thread woke up");
} catch (InterruptedException e) {
e.printStackTrace();
}join()
join()方法等待线程终止。调用该方法的线程会等待被调用线程执行完毕后再继续执行。
public class Main {
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
try {
Thread.sleep(1000); // 模拟工作
System.out.println("Thread finished");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t1.start();
try {
t1.join(); // 等待 t1 线程结束
System.out.println("Main thread continues");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}currentThread()
currentThread()方法用于获取当前正在执行的线程(线程对象的引用)
public class Main {
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
Thread currentThread = Thread.currentThread();
System.out.println("Current thread: " + currentThread.getName());
});
t1.start();
}
}interrupt() isInterrupted() interrupted()
interrupt()
interrupt()方法用于设置线程中断状态为true。
线程.isInterrupted()
isInterrupted()方法用于检查线程是否被中断,但不会重置中断标志。它返回一个布尔值
Thread.interrupted()
检查当前线程的中断状态,并重置中断标志为 false。
具体来说,当一个线程调用interrupt()方法时:
- 如果一个线程处理正常活动状态,那么会将该线程的中断标志设为为true,仅此而已。被设置中断标志的线程将继续运行,不受影响。
- 所以,interrupt()方法并不能真正的中断线程,需要被调用的线程自己进行配合才行
- 源码叙述:interrupt()方法中断一个不活动的线程不会产生任何影响。
- 如果线程处于被阻塞状态(例如处于sleep、wait、join等),在别的线程中调用当前线程对象的interrupt()方法,那么线程将立即退出被阻塞状态,并抛出
InterruptedException异常
方法区分
| 方法 | 描述 |
|---|---|
| public void interrupt() | 实例方法。设置线程的中断状态为true,发起一个协商而不会立即停止线程 // Just to set the interrupt flag |
| public static boolean interrupted() | 静态方法。判断线程是否被中断并清除当前中断状态。 这个方法做了两件事情: 1、返回当前线程的中断状态 2、将当前的中断状态清零并重设为false,清理线程的中断状态 |
| public boolean isInterrupted() | 实例方法。判断当前线程是否已被中断 |
示例:
public class Main {
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
try {
while (!Thread.currentThread().isInterrupted()) { // 判断线程是否被中断
System.out.println("Thread is running");
Thread.sleep(500);
}
} catch (InterruptedException e) {
System.out.println("Thread was interrupted");
}
});
t1.start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
t1.interrupt(); // 中断 t1 线程
}
}setPriority(int newPriority)
setPriority(int newPriority)方法用于设置线程的优先级。
优先级范围从Thread.MIN_PRIORITY(1) 到 Thread.MAX_PRIORITY(10),默认优先级为Thread.NORM_PRIORITY(5)。
getPriority()
getPriority()方法用于获取线程的优先级
public class Main {
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
System.out.println("Thread is running with priority: " + Thread.currentThread().getPriority());
});
t1.setPriority(Thread.MAX_PRIORITY);
t1.start();
}
}setName(String name)
setName(String name)方法用于设置线程的名称
getName()
getName()方法用于获取线程的名称
public class Main {
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
System.out.println("Thread name: " + Thread.currentThread().getName());
});
t1.setName("MyThread");
t1.start();
}
}yield()
yield()方法它使得当前线程从运行状态(Running)进入到就绪状态(Runnable),给其他具有相同优先级的等待线程以执行的机会。
- 不确定性:调用 yield 不一定会导致当前线程停止执行,因为调度器可能会再次选择该线程继续运行。
- 使用场景:通常在希望多个同优先级的线程能够更加“公平”地获得 CPU 时间时使用,但实际效果依赖于 JVM 和底层操作系统的线程调度策略。
class YieldExample {
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5; i++) {
System.out.println("Thread 1: " + i);
if (i == 2) Thread.yield(); // 尝试让出CPU
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5; i++) {
System.out.println("Thread 2: " + i);
}
});
t1.start();
t2.start();
}
}其他
此外,还有如下这些方法
public final native boolean isAlive() // 判断线程是否还活着
// @since 1.5
public State getState() // 得到这一线程的状态
// 将指定线程设置为守护线程
public final void setDaemon(boolean on)
// 必须在线程启动start()之前设置,否则会报 IllegalThreadStateException 异常。
// 判断线程是否是守护线程
public final boolean isDaemon()
// 以下三个方法已过时,不建议使用
public final void stop() // 强行结束一个线程的执行,直接进入死亡状态。run()即刻停止,可能会导致一些清理性的工作得不到完成,如文件,数据库等的关闭。同时,会立即释放该线程所持有的所有的锁,导致数据得不到同步的处理,出现数据不一致的问题。
// 二者必须成对出现,否则非常容易发生死锁。
public final void suspend() // 会导致线程暂停,但不会释放任何锁资源,导致其它线程都无法访问被它占用的锁,直到调用 resume()
public final void resume() // 恢复线程。该方法仅用于调用suspend()之后调用Java创建线程的方式有哪些?
Java语言的JVM允许程序运行多个线程,使用java.lang.Thread类代表线程,所有的线程对象都必须是Thread类或其子类的实例。
Thread类的特性
- 每个线程都是通过某个特定Thread对象的run()方法来完成操作的,因此把run()方法体称为线程执行体。
- 通过该Thread对象的start()方法来启动这个线程,而非直接调用run()(如果使用Thread方法直接调用run方法,相当于main线程在执行该方法)
- 要想实现多线程,必须在主线程中创建新的线程对象
在学习线程的创建方式之前需要明白:下面的方式都只是创建线程的方式,本质上线程的创建方式只有一种,那就是Thread.start()
- 继承Thread类
- 实现Runnable接口
- 实现Callable接口
- 使用线程池
方式1:继承Thread类
通过继承java.lang.Thread类并重写其run方法来创建线程:
- 定义Thread类的子类,并重写该类的run()方法,该run()方法的方法体就代表了线程需要完成的任务
- 创建Thread子类的实例,即创建了线程对象
- 调用线程对象的start()方法来启动该线程
public class EvenNumberDemo {
public static void main(String[] args) {
EvenNumberThread evenNumberThread = new EvenNumberThread();
evenNumberThread.start(); // 启动子线程
// 主方法的逻辑
for (int i = 1; i < 100; i++) {
if (i % 2 == 0) {
System.out.println(Thread.currentThread().getName() + ":" + i);
}
}
}
}
// 为了方便,我们直接在这里定义一个类
class EvenNumberThread extends Thread {
@Override
public void run() {
for (int i = 1; i < 100; i++) { // 遍历1-100内的偶数
if (i % 2 == 0) {
System.out.println(Thread.currentThread().getName() + ":" + i);
}
}
}
}注意:
- 如果自己手动调用run()方法,那么就只是普通方法,没有启动多线程模式。
- run()方法由JVM调用,什么时候调用,执行的过程控制都由操作系统的CPU调度决定。
- 想要启动多线程,必须调用start方法。
- 一个线程对象只能调用一次start()方法启动线程,如果重复调用了,则将抛出以上的异常
IllegalThreadStateException
方式2:实现Runnable接口
通过实现java.lang.Runnable接口并将其传递给Thread对象来创建线程
Java有单继承的限制,当我们无法继承Thread类时,那么该如何做呢?在核心类库中提供了Runnable接口,我们可以实现Runnable接口,重写run()方法,然后再通过Thread类的对象代理启动和执行我们的线程体run()方法
步骤如下:
- 定义Runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
- 创建Runnable实现类的实例,并以此实例作为Thread的target参数来创建Thread对象,该Thread对象才是真正的线程对象。
- 调用线程对象的start()方法,启动线程。调用Runnable接口实现类的run方法
public class OddNumberDemo {
public static void main(String[] args) {
//创建自定义类对象 线程任务对象
OddNumberRunnable oddNumberRunnable = new OddNumberRunnable();
//创建线程对象,并启动线程
new Thread(oddNumberRunnable).start();
// 主方法的逻辑
for (int i = 0; i < 100; i++) { // 打印1-100以内的奇数
if (i % 2 == 1) {
System.out.println(Thread.currentThread().getName() + ":" + i);
}
}
}
}
class OddNumberRunnable implements Runnable {
@Override
public void run() {
for (int i = 0; i < 100; i++) { // 打印1-100以内的奇数
if (i % 2 == 1) {
System.out.println(Thread.currentThread().getName() + ":" + i);
}
}
}
}注意:
- 通过实现Runnable接口,使得该类有了多线程类的特征。所有的分线程要执行的代码都在run方法里面。
- 在启动的多线程的时候,需要先通过Thread类的构造方法Thread(Runnable target) 构造出对象,然后调用Thread对象的start()方法来运行多线程代码。
- 实际上,所有的多线程代码都是通过运行Thread的start()方法来运行的。因此,不管是继承Thread类还是实现 Runnable接口来实现多线程,最终还是通过Thread的对象的API来控制线程的,熟悉Thread类的API是进行多线程编程的基础。
- 说明:Runnable对象仅仅作为Thread对象的target,Runnable实现类里包含的run()方法仅作为线程执行体。 而实际的线程对象依然是Thread实例,只是该Thread线程负责执行其target的run()方法。
方式二:使用Lambda表达式简化Runnable接口的实现
通过Lambda表达式简化Runnable接口的实现
public class OddNumberDemo {
public static void main(String[] args) {
//创建线程对象,并启动线程
new Thread(()->{ for (int i = 0; i < 100; i++) {
if (i % 2 == 1) { // 遍历100以内的奇数
System.out.println(Thread.currentThread().getName() + ":" + i);
}
}},"老六线程").start();
// 主方法的逻辑
for (int i = 0; i < 100; i++) { // 打印1-100以内的奇数
if (i % 2 == 1) {
System.out.println(Thread.currentThread().getName() + ":" + i);
}
}
}
}方式三:实现Callable接口(JDK5.0增加)
通过实现java.util.concurrent.Callable接口来创建线程,并使用FutureTask来管理返回结果。
- 与使用 Runnable 相比, Callable 功能更强大些
- 相比 run()方法,可以有返回值
- call()方法可以抛出异常
- 支持泛型的返回值(需要借助 FutureTask 类,获取返回结果)
- Future 接口
- 可以对具体 Runnable、Callable 任务的执行结果进行取消、查询是否完成、获取结果等。
- FutureTask 是 Futrue 接口的唯一的实现类
- FutureTask 同时实现了
Runnable,`Future 接口。它既可以作为 Runnable 被线程执行,又可以作为 Future 得到 Callable 的返回值
- 缺点:在获取分线程执行结果的时候(即调用get方法),当前线程(或是主线程)受阻塞,效率较低。
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
// jdk5.0新增的创建线程的方式:实现Callable
// 1.创建一个类实现 Callable
class NumThread implements Callable {
// 2.实现 call 方法,将此线程要执行的操作声明在方法内
@Override
public Object call() throws Exception {
// 执行任务逻辑,返回结果
int sum = 0;
for (int i = 1; i <= 100; i++) {
if (i % 2 == 0) {
System.out.println(i);
sum += i;
}
}
return sum;
}
}
public class CallableTest {
public static void main(String[] args) {
// 3.创建Callable接口的实现类对象
NumThread numThread = new NumThread();
// 4.将此Callable接口的实现类对象作为参数传递到FutureTask构造器中,创建FutureTask的对象
FutureTask futureTask = new FutureTask(numThread);
// 5.将FutureTask的对象作为参数传递到Thread类的构造器中,创建Thread对象,并调用start()
Thread t1 = new Thread(futureTask);
t1.start();
try {
// 6.获取Callable中的返回值(执行任务逻辑,返回结果)
// get()返回值即为FutureTask构造器参数Callable实现类重写的call()的返回值
Object sum = futureTask.get(); // todo get方法自然会有阻塞,等待t1执行完以后,再取返回值
System.out.println("sum this is " + sum);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}方式四:使用线程池
通过java.util.concurrent.ExecutorService接口的实现类创建和管理线程池,避免手动创建和管理线程。
使用线程池的好处:
- 提高响应速度(减少了创建新线程的时间)
- 降低资源消耗(重复利用线程池中线程,不需要每次都创建)
- 便于线程管理
- corePoolSize:核心池的大小
- maximumPoolSize:最大线程数
- keepAliveTime:线程没有任务时最多保持多长时间后会终止
在 Java 中,可以使用 java.util.concurrent 包中的 ExecutorService 接口和 ThreadPoolExecutor 类来创建和管理线程池。
线程池核心思想:用固定的线程去执行不定量的task
使用线程池的一般步骤
- 1)创建线程池对象:可以使用
Executors类的静态方法来创建线程池对象
// 例如,可以使用 Executors.newFixedThreadPool(int nThreads) 方法创建一个固定大小的线程池。
ExecutorService executor = Executors.newFixedThreadPool(5);- 2)提交任务给线程池:使用
execute(Runnable command)方法或submit(Callable<T> task)方法将任务提交给线程池。execute方法用于提交不需要返回结果的任务,而submit方法用于提交需要返回结果的任务。
executor.execute(new MyRunnable());
executor.submit(new MyCallable());- 3)定义任务:任务可以是实现了
Runnable接口的类或实现了Callable接口的类。Runnable接口的run方法定义了任务的执行逻辑,Callable接口的call方法也定义了任务的执行逻辑,并且可以返回一个结果。
class MyRunnable implements Runnable {
public void run() {
// 任务的执行逻辑
}
}
class MyCallable implements Callable<Integer> {
public Integer call() {
// 任务的执行逻辑,并返回一个结果
return 42;
}
}- 4)关闭线程池:在不再需要线程池时,应该调用
shutdown()方法来关闭线程池。这将停止接受新的任务,并等待已提交的任务完成。
executor.shutdown(); 以上是使用线程池的基本步骤。您还可以根据需要设置线程池的参数,如线程池大小、任务队列类型等。可以通过 ThreadPoolExecutor 类的构造函数或 ExecutorService 接口的其他方法来进行配置
示例:
通过 ThreadPoolExecutor类的构造器创建线程池
import java.util.concurrent.*;
// 线程池:JDK5.0增加的线程创建方式
// 使用 execute()方法提交线程任务,无返回值
public class ThreadPoolDemo1 {
public static void main(String[] args) {
/**
public ThreadPoolExecutor(int corePoolSize, 核心线程数量
int maximumPoolSize, 最大线程池数量
long keepAliveTime, 非核心线程的空闲时间
TimeUnit unit, 空闲时间单位
BlockingQueue<Runnable> workQueue, 任务队列
ThreadFactory threadFactory, 线程工厂
RejectedExecutionHandler handler 拒绝策略
)
*/
// todo 1.创建线程池对象
ExecutorService pool = new ThreadPoolExecutor(3, 5, 6,
TimeUnit.SECONDS, new ArrayBlockingQueue<>(5),
Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy());
// todo 2.将任务给线程池处理,通过 execute()方法提交
Runnable target = new MyRunnable();
pool.execute(target);
pool.execute(target);
pool.execute(target);
// 放入任务队列
pool.execute(target);
pool.execute(target);
pool.execute(target);
pool.execute(target);
pool.execute(target);
// 开始创建临时线程
pool.execute(target);
pool.execute(target);
// 不创建,拒绝策略被触发!!
pool.execute(target); // 抛出异常 RejectedExecutionException
// todo 4.关闭线程池
//pool.shutdownNow(); // 立即关闭,即使任务没有执行完,会丢失任务
pool.shutdown(); // 会等待任务执行完毕后才完毕(可以使用)
}
}
// todo 3.定义任务
public class MyRunnable implements Runnable {
@Override
public void run() {
for (int i = 0; i < 2; i++) {
System.out.println(Thread.currentThread().getName() + "输出了:HelloWorld ==>" + i);
}
try {
System.out.println("本任务与线程"+ Thread.currentThread().getName()+ "进行绑定,线程进入休眠");
Thread.sleep(500000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}通过 Executors 工厂类使用线程池(阿里规约曰禁止使用)
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
// 使用 Executors静态工厂方法创建线程池对象
public class ThreadPoolTest {
public static void main(String[] args) {
// todo 1.获取一个指定线程数量的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(5);
// todo 2.提交任务给线程池,并且使用匿名内部类的方式定义任务
threadPool.execute(() -> {
int sum = 0;
for (int i = 1; i <= 100; i++) {
if (i % 2 == 0) {
sum += i;
}
}
System.out.println("sum this is " + sum);
});
threadPool.execute(() -> System.out.println("hello world"));
threadPool.execute(() -> System.out.println("hello world"));
threadPool.execute(() -> System.out.println("hello world"));
threadPool.execute(() -> System.out.println("hello world"));
// todo 4.关闭线程池
threadPool.shutdown();
}
}Java创建线程的几种方式有什么区别?
继承Thread类
实现方式:通过继承
java.lang.Thread类并重写run()方法。特点:
- 简单直接,适合简单的场景。
- 受限于 Java 的单继承机制,如果类已经继承了其他类,则不能使用这种方式。
- 不支持返回值:任务执行完毕后无法返回结果。
适用场景:非常基础的并发需求,代码量较少且不需要复杂功能。不适合复杂的线程管理和资源共享场景
实现Runnable接口
- 实现方式:通过实现
java.lang.Runnable接口并重写run()方法,然后将 Runnable 实例传递给 Thread 类的构造函数。 - 特点:
- 避免了单继承限制,灵活性更高(因为类可以实现多个接口)。
- 资源共享:多个线程可以共享同一个 Runnable 实例,便于资源共享。
- 不支持返回值:任务执行完毕后无法返回结果
- 适用场景:大多数并发编程场景,尤其是需要多个线程执行相同任务时。
实现Callable接口和使用FutureTask
实现方式:通过实现
java.util.concurrent.Callable接口并重写call()方法。与 Runnable 不同,Callable 可以返回结果并且可以抛出异常。但实现和使用稍微复杂一些。特点:
- 支持返回值和异常处理,适用于需要返回结果的任务。
- 通常与 Future 和 ExecutorService 一起使用,便于管理和获取任务结果。(使用FutureTask来管理和返回结果)
适用场景:需要任务返回结果或处理异常的场景。
使用线程池
实现方式:通过
java.util.concurrent.ExecutorService来管理线程的创建和执行。ExecutorService 提供了线程池管理功能,如固定大小的线程池、缓存线程池、定时线程池等。特点
- 线程池管理:通过线程池复用线程,减少频繁创建和销毁线程的开销。
- 任务调度:支持异步任务提交和结果获取。
- 灵活配置:可以根据任务量动态调整线程池大小。可以根据需求选择不同类型的线程池(如固定大小、缓存、定时等)。
- 简化开发:隐藏了线程管理的复杂性,使代码更加简洁和易于维护。
适用场景:需要高效管理和复用线程的场景,特别是高并发环境。
为什么不建议使用Executors来创建线程池?(阿里规约)
Executors:一个线程池的工厂类,通过此类的静态工厂方法可以创建多种类型的线程池对象。
Executors提供了4个常用方法来创建内置的线程池
1、newFixedThreadPool
Executors.newFixedThreadPool(int nThreads):创建一个可重用固定线程数的线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}发现创建的队列为LinkedBlockingQueue,是一个无界阻塞队列,如果使用改线程池执行任务,如果任务过多就会不断的添加到队列中,任务越多占用的内存就越多,最终可能耗尽内存,导致OOM
2、SingleThreadExecutor
Executors.newSingleThreadExecutor() :创建一个只有一个线程的线程池
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}发现创建的队列为LinkedBlockingQueue,是一个无界阻塞队列,如果使用改线程池执行任务,如果任务过多就会不断的添加到队列中,任务越多占用的内存就越多,最终可能耗尽内存,导致OOM
3、CachedThreadPool
Executors.newCachedThreadPool():创建一个可根据需要创建新线程的线程池
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}它的特点是线程数不受限制,可以根据需要创建新线程。虽然这对于短时间的任务非常有用,但如果任务执行时间较长或任务量较大,可能会导致大量线程堆积,从而消耗过多系统资源,最终导致OOM
4、ScheduledThreadPool
Executors.newScheduledThreadPool(int corePoolSize):创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}阿里规约

线程池相关的常用API?
JDK5.0 之前,我们必须手动自定义线程池。从 JDK5.0 开始,Java 内置线程池相关的API。在 java.util.concurrent 包下提供了线程池相关 API:ExecutorService接口 和 Executors工厂类。
- ExecutorService:真正的线程池接口。常见子类 ThreadPoolExecutor
void execute(Runnable command):执行任务/命令,没有返回值,一般用来执行 Runnable<T> Future<T> submit(Callable<T> task):执行任务,有返回值,一般又来执行 Callablevoid shutdown():关闭连接池
- Executors:一个线程池的工厂类,通过此类的静态工厂方法可以创建多种类型的线程池对象。
Executors.newCachedThreadPool():创建一个可根据需要创建新线程的线程池Executors.newFixedThreadPool(int nThreads):创建一个可重用固定线程数的线程池Executors.newSingleThreadExecutor():创建一个只有一个线程的线程池Executors.newScheduledThreadPool(int corePoolSize):创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
下面是java.util.concurrent包下 ThreadPoolExecutor 类中参数最多的一个构造器
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
// corePoolSize:线程池的核心线程数。在没有任务执行时,线程池会保持这些核心线程的数量。
// 即使这些线程处于空闲状态,它们也不会被销毁。当有新的任务提交时,线程池会优先使用核心线程来执行任务。
// maximumPoolSize:线程池的最大线程数。线程池中允许创建的最大线程数,包括核心线程和非核心线程。
// 当任务提交的数量超过核心线程数,并且任务队列已满时,线程池会创建新的非核心线程来执行任务,直到达到最大线程数。
// keepAliveTime:非核心线程的空闲时间。当线程池中的线程数量超过核心线程数时,空闲的非核心线程会在指定的时间内保持存活状态。如果在这段时间内没有新的任务提交,这些线程将被销毁。
// unit:空闲时间的时间单位。指定 keepAliveTime 参数的时间单位,例如 TimeUnit.SECONDS 表示秒。
// workQueue:任务队列。用于存储待执行的任务的阻塞队列。当线程池中的线程都在执行任务时,新的任务会被放入任务队列中等待执行。
// threadFactory:线程工厂。用于创建新线程的工厂对象。可以自定义线程的创建逻辑,例如设置线程的名称、优先级等。
- SynchronousQueue:直接提交队列
- ArrayBlockingQueue:有界队列,可以指定容量
- LinkedBlockingQueue:有界|无界队列
- PriorityBlockingQueue:优先任务队列,可以根据任务的优先级顺序执行
- DelayQueue:延迟任务
// handler:拒绝策略。当线程池已经达到最大线程数,并且任务队列已满时,新的任务无法提交时,会触发拒绝策略来处理这些被拒绝的任务。
// 可以使用预定义的拒绝策略,如 ThreadPoolExecutor.AbortPolicy、ThreadPoolExecutor.DiscardPolicy、ThreadPoolExecutor.DiscardOldestPolicy 或自定义的拒绝策略。BlockingQueue是什么?
BlockingQueue是 Java 中定义在java.util.concurrent包下的一个接口,它扩展了Queue接口,并添加了阻塞操作。BlockingQueue提供了一种线程安全的机制,用于在多线程环境中处理生产者-消费者问题。
特点
- 线程安全:所有方法都使用内部锁或其他同步机制来确保线程安全
- 阻塞操作:当队列为空时,从队列中取元素会被阻塞,直到有元素加入;当队列满时,往队列中添加元素会被阻塞,直到有空间可用。
常用方法:
put(E e):将指定元素插入此队列中,如果该队列已满,则等待空间变得可用。take():从此队列中获取并移除头部元素,如果此队列为空,则等待元素变得可用。offer(E e, long timeout, TimeUnit unit):尝试在指定的等待时间内将指定元素插入此队列,如果超时则返回false。poll(long timeout, TimeUnit unit):尝试在指定的等待时间内从此队列中获取并移除头部元素,如果超时则返回null。
常见的BlockingQueue有实现方式
ArrayBlockingQueue:基于数组的有界阻塞队列。需要在初始化时指定队列大小,队列满时,生产者会被阻塞,队列空时,消费者会被阻塞
LinkedBlockingQueue:基于链表的阻塞队列,允许可选的界限(有界或无界)。无界模式下,可以不断添加元素,直到耗尽系统资源。有界模式下类似于ArrayBlockingQueue,但吞吐量通常较高
PriorityBlockingQueue:支持优先级排序的无界阻塞队列。元素按照自然排序或比较器顺序排序。与其他队列不同,此队列不保证元素的FIFO顺序
DelayQueue:支持延迟元素的无界阻塞队列。只有在延迟期满时才能从中提取元素的无界阻塞队列。常用于任务调度
SynchronousQueue:不存储元素的阻塞队列,每个插入操作必须等待一个对应的移除操作。反之亦然。常用于在线程直接的直接传递任务,而不是存储任务。
扩展
- LinkedTransferQueue:基于链表的无界阻塞队列,支持传输操作(即元素入队时判断是否已有消费者在等待,如果有,直接将数据给消费者,这里没有锁操作)
使用场景
ArrayBlockingQueue 和 LinkedBlockingQueue常用于典型的生产者-消费者场景。
PriorityBlockingQueue 更适用于处理带有优先级的任务场景,如任务调度系统
DelayQueue 使用于需要延迟处理的任务,例如:缓存失效处理、定时任务调度等
SynchronousQueue:适合在线程间直接传递数据,而不希望数据存储在队列中。例如:ThreadPoolExecutor的直接交付模式中使用SynchronousQueue来传递任务
使用BlockingQueue实现生产者-消费者模式:
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class BlockingQueueExample {
public static void main(String[] args) {
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>(5);
// 生产者线程
Thread producer = new Thread(() -> {
try {
for (int i = 0; i < 10; i++) {
System.out.println("Producing: " + i);
queue.put(i); // 如果队列已满,阻塞
Thread.sleep(100); // 模拟生产时间
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
// 消费者线程
Thread consumer = new Thread(() -> {
try {
for (int i = 0; i < 10; i++) {
Integer value = queue.take(); // 如果队列为空,阻塞
System.out.println("Consuming: " + value);
Thread.sleep(150); // 模拟消费时间
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
producer.start();
consumer.start();
}
}主要方法
BlockingQueue提供了一些常用的方法,这些方法分为四类:
抛出异常:
add(E e):如果队列已满,抛出IllegalStateException。
remove():如果队列为空,抛出NoSuchElementException。
element():如果队列为空,抛出NoSuchElementException。
返回特殊值:
offer(E e):如果队列已满,返回false。
poll():如果队列为空,返回null。
peek():如果队列为空,返回null。
阻塞操作:
put(E e):如果队列已满,阻塞直到有空间可插入元素。
take():如果队列为空,阻塞直到有元素可取。
超时操作:
offer(E e, long timeout, TimeUnit unit):在指定的时间内插入元素,如果队列已满,等待直到超时或插入成功。
poll(long timeout, TimeUnit unit):在指定的时间内取出元素,如果队列为空,等待直到超时或取出成功。
ArrayBlockingQueue 与 LinkedBlockingQueue区别
ArrayBlockingQueue 与 LinkedBlockingQueue分别是基于数组和链表的有界阻塞队列,后者也至此无界队列
两者的原理都是基于 ReentrantLock 和 Condition
ArrayBlockingQueue 基于数组,内部实现只用了一把锁,可以指定公平或非公平
LinkedBlockingQueue 基于链表,内部实现用了两把锁,take一把、put一把,所以入队和出队两个操作是可以并行的,从这里看并发度应该比ArrayBlockingQueue 高
Java中有哪些队列?
LinkedList
基于链表实现的双向链表,实现了List、Deque和Queue接口,支持在头部和尾部进行快速插入和删除操作。
使用场景:
需要频繁插入和删除元素的场景。
需要双端队列(Deque)功能的场景,如在头部和尾部进行操作。
PriorityQueue
基于优先级堆(Priority Heap)实现的无界队列。元素按照自然顺序或指定的比较器顺序排列。不允许插入null元素。
使用场景:
需要按优先级处理元素的场景,如任务调度、事件处理等。
需要动态调整元素顺序的场景。
ArrayDeque
基于数组实现的双端队列(Deque),没有容量限制,可以动态扩展,比LinkedList更高效,尤其是在栈和队列操作方面。
使用场景:
需要高效的栈或队列操作的场景。
需要双端队列功能,但不需要线程安全的场景。
ConcurrentLinkedQueue
基于链表实现的无界非阻塞队列。使用无锁算法,提供高效的并发性能。线程安全,适用于高并发环境。
使用场景:
高并发环境下的无界队列。
需要高效的非阻塞并发操作的场景
LinkedBlockingQueue
基于链表实现的可选(有界或无界)阻塞队列,支持阻塞的put和take操作,线程安全,适用于生产者-消费者模式。
使用场景:
生产者-消费者模式,特别是在需要限制队列大小的场景。需要线程安全的阻塞队列。
ArrayBlockingQueue
基于数组实现的有界阻塞队列,必须指定容量,支持阻塞的put和take操作。线程安全,适用于生产者-消费者模式。
使用场景:
生产者-消费者模式,特别是在需要固定大小的队列时。需要线程安全的有界阻塞队列。
DelayQueue
支持延迟元素的无界阻塞队列,元素只有在其延迟时间到期后才能被取出。线程安全,适用于并发环境。
使用场景:
需要延迟处理元素的场景,如任务调度、缓存过期处理等。
定时任务执行场景。
LinkedBlockingDeque
基于链表实现的可选有界阻塞双端队列,支持阻塞的put和take操作。线程安全,适用于生产者-消费者模式。
使用场景:生产者-消费者模式,特别是在需要限制队列大小的双端队列场景。需要线程安全的阻塞双端队列。
阻塞队列原理?
阻塞队列是一种线程安全的队列,它在插入和删除操作上可以阻塞线程,以实现生产者-消费者模式等并发编程需求。阻塞队列的核心原理包括锁机制和条件变量。
基本原理
锁机制
阻塞队列使用锁(如ReentrantLock)来确保线程安全。锁保证了同一时间只有一个线程可以执行插入或删除操作,从而避免并发问题
条件变量
阻塞队列使用条件变量(Condition)来管理线程的等待和通知。条件变量是与锁关联的,可以在特定条件下阻塞线程并在条件满足时唤醒线程。例如,notEmpty和notFull是常见的条件变量,分别用于表示队列是否为空和是否已满。
等待和通知机制
当线程试图执行插入操作而队列已满时,它会在notFull条件变量上等待,直到队列中有空闲空间。
当线程试图执行删除操作而队列为空时,它会在notEmpty条件变量上等待,直到队列中有可用的元素。
当插入或删除操作成功后,相应的条件变量会被通知(唤醒),以便其他等待的线程可以继续执行。
为什么启动线程不直接调用run(),而调用start()?
想要启动多线程,必须调用start()方法。
一个线程对象只能调用一次start()方法启动线程,如果重复调用会抛出IllegalThreadStateException异常
start()方法
start()方法的作用是启动一个新线程,并且使该线程进入就绪状态,等待操作系统的线程调度器来调度它执行。
当你调用start()方法时,Java虚拟机会创建一个新的执行线程。在这个新的线程中,Java虚拟机会自动调用run()方法。
调用start()方法后,原来的线程和新创建的线程可以并发执行
run()方法
run()方法包含了线程执行的代码,是你需要在新线程中执行的任务。
如果直接调用run()方法,run()方法会在当前线程中执行,而不会启动一个新线程。(失去了创建线程的意义)
直接调用run()方法不会创建新的线程,所有代码在调用run()方法的线程中顺序执行
为什么不能直接调用run()方法
- 启动新线程:start()方法负责启动一个新线程,而直接调用run()只是普通的方法调用,不会启动新线程。
- 并发执行:通过start()方法启动的新线程可以与原来的线程并发执行,而直接调用run()方法则是在当前线程中顺序执行。
- 线程状态管理:start()方法会使线程进入就绪状态,等待操作系统调度,而直接调用run()方法不会改变线程的状态管理
- 如果自己手动调用run()方法,那么就只是普通方法,不会启动新线程。
- run()方法由JVM调用,什么时候调用,执行的过程控制都由操作系统的CPU调度决定。
- 我们创建线程的目的是为了更充分地利用CPU资源,如果直接调用run()方法,就失去了创建线程的意义
- start()方法是Java线程中约定的内置方法,能够确保代码在新的线程上下文中执行
- start()方法包含了除创建新线程的特殊代码逻辑。run()方法是我们自己写的代码,显然没有这个能力
- 想要启动多线程,必须调用start方法。
- 一个线程对象只能调用一次start()方法启动线程,如果重复调用了,则将抛出以上的异常
IllegalThreadStateException。
两次调用start方法会怎么样?
第一次调用start方法时,线程可能处于终止或其他非NEW状态,再次调用start()方法会让正在运行的线程重新运行一遍。
不管是从线程安全的角度来看 ,还是从线程本身的执行逻辑来看 ,他都是不合理的。因此为了避免这种问题的出现,Java中会先判断线程的运行状态。
可调用如下方法确定当前线程的状态
public State getState() // 得到线程的当前状态
// NEW,RUNNABLE,BLOCKED,WAITING,TIMED_WAITING,TERMINATED;注意:
程序只能对新建状态(NEW)的线程调用 start(),并且只能调用一次,如果对非新建状态的线程,如已启动的线程或已死亡的线程调用 start()都会报错
IllegalThreadStateException异常。
这个问题的关键点在于:
只能对新建状态(NEW)的线程调用 start()
怎么理解线程分组?编程实现一个线程分组的例子?
线程分组(Thread Group)是一种将多个线程组织在一起的机制,主要用于管理和控制一组线程的行为。通过线程分组,可以方便地对一组线程进行批量操作,例如启动、中断或监控。
每个线程在创建是都会被分配到一个线程租,默认情况下,主线程会被分配到一个名为main的线程组。
在 Java 中,ThreadGroup 类提供了对线程分组的支持。每个线程都属于一个线程组,线程组可以包含多个线程,也可以嵌套其他线程组,从而形成一种树状结构。
线程分组的主要用途
统一管理:可以对一组线程进行统一的操作,比如中断所有线程。
资源隔离:通过分组,可以将不同功能的线程隔离开来,便于调试和维护。
异常处理:线程组可以捕获其内部线程未捕获的异常,提供全局异常处理的能力。
示例:
public class ThreadGroupExample {
public static void main(String[] args) {
// 创建一个线程组
ThreadGroup group = new ThreadGroup("MyThreadGroup");
// 创建并启动多个线程,加入到线程组中
Thread thread1 = new Thread(group, () -> {
for (int i = 0; i < 5; i++) {
System.out.println(Thread.currentThread().getName() + " is running");
try {
Thread.sleep(500); // 模拟任务执行
} catch (InterruptedException e) {
System.out.println(Thread.currentThread().getName() + " was interrupted");
}
}
}, "Thread-1");
Thread thread2 = new Thread(group, () -> {
for (int i = 0; i < 5; i++) {
System.out.println(Thread.currentThread().getName() + " is running");
try {
Thread.sleep(500); // 模拟任务执行
} catch (InterruptedException e) {
System.out.println(Thread.currentThread().getName() + " was interrupted");
}
}
}, "Thread-2");
// 启动线程
thread1.start();
thread2.start();
// 打印线程组信息
System.out.println("Active threads in group: " + group.activeCount());
// 中断线程组中的所有线程
try {
Thread.sleep(2000); // 主线程等待一段时间
System.out.println("Interrupting all threads in the group...");
group.interrupt(); // 中断线程组中的所有线程
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}在这个例子中,创建了一个名为MyThreadGroup 的线程组,并将线程thread1、thread2加入到了这个线程组中,接着启动所有线程,打印了MyThreadGroup 的线程组内活动线程的数量,2s后中断这个线程组中的所有线程。
注意事项
- 线程组的局限性
- ThreadGroup 在现代 Java 开发中使用较少,因为它的功能有限,且容易导致复杂性和潜在问题(如异常处理不够灵活)。
- 更推荐使用高级并发工具(如 ExecutorService 和 ForkJoinPool)来管理线程。
- 异常处理
- 如果线程组中的某个线程抛出未捕获的异常,可以通过重写 ThreadGroup.uncaughtException(Thread t, Throwable e) 方法来处理。
- 线程组的嵌套
- 线程组支持嵌套,即一个线程组可以包含另一个线程组,形成树状结构。
线程的状态有哪几种?
jdk1.5之前的五种状态
线程的生命周期有五种状态:新建(New)、就绪(Runnable)、运行 (Running)、阻塞(Blocked)、死亡(Dead)。CPU 需要在多条线程之间切换,于是线程状态会多次在运行、阻塞、就绪之间切换**。**
(这是一种临时状态)
|------------阻塞<---------------|
sleep()时间到 | | sleep()
join线程结束 | | join()
获得同步锁 | | 等待同步锁
notify()\notifyAll()| | wait()
resume() v | suspend()
获得cpu执行权 | (线程的最终状态)
新建 =============> 就绪 <=========================> 运行 ====================>死亡
start() 失去cpu执行权(时间片用完) run()正常结束
yield() 出现未处理的Error\Exception
stop()新建(New)
当一个 Thread 类或其子类的对象被声明并创建时,新生的线程对象处于新建状态。此时它和其他 Java 对象一样,仅仅由 JVM 为其分配了内存,并初始化了实例变量的值。此时的线程对象并没有任何线程的动态特征,程序也不会执行它的线程体run()
就绪(Runnable)
但是当线程对象调用了 start()方法之后,就不一样了,线程就从新建状态转为就绪状态。JVM 会为其创建方法调用栈和程序计数器,当然,处于这个状态中的线程并没有开始运行,只是表示已具备了运行的条件,随时可以被调度。至于什么时候被调度,取决于 JVM 里线程调度器的调度。
注意:
程序只能对新建状态的线程调用 start(),并且只能调用一次,如果对非新建状态的线程,如已启动的线程或已死亡的线程调用 start()都会报错 IllegalThreadStateException 异常。
运行 (Running)
如果处于就绪状态的线程获得了CPU资源时,开始执行 run()方法的线程体代码,则该线程处于运行状态。如果计算机只有一个 CPU 核心,在任何时刻只有一个线程处于运行状态,如果计算机有多个核心,将会有多个线程并行
(Parallel)执行
当然,美好的时光总是短暂的,而且 CPU 讲究雨露均沾。对于抢占式策略的系统而言,系统会给每个可执行的线程一个小时间片来处理任务,当该时间用完,系统会剥夺该线程所占用的资源,让其回到就绪状态等待下一次被调度。
此时其他线程将获得执行机会,而在选择下一个线程时,系统会适当考虑线程的优先级
阻塞(Blocked)
当在运行过程中的线程遇到如下情况时,会让出CPU并临时中止自己的执行,进入阻塞状态:
- 线程调用了 **sleep()**方法,主动放弃所占用的 CPU 资源;
- 线程试图获取一个同步监视器,但该同步监视器正被其他线程持有;
- 线程执行过程中,同步监视器调用了 wait(),让它等待某个通知(notify);
- 线程执行过程中,同步监视器调用了 wait(time)
- 线程执行过程中,遇到了其他线程对象的加塞(join);
- 线程被调用 suspend 方法被挂起(已过时,因为容易发生死锁);
当前正在执行的线程被阻塞后,其他线程就有机会执行了。针对如上情况,当发生如下情况时会解除阻塞,让该线程重新进入就绪状态,等待线程调度器再次调度它:
- 线程的 sleep()时间到;
- 线程成功获得了同步监视器;
- 线程等到了通知(notify);
- 线程 wait 的时间到了
- 加塞的线程结束了;
- 被挂起的线程又被调用了 resume 恢复方法(已过时,因为容易发生死锁);
死亡(Dead)
线程会以以下三种方式之一结束,结束后的线程就处于死亡状态:
- run()方法执行完成,线程正常结束
- 线程执行过程中抛出了一个未捕获的异常(Exception)或错误(Error)
- 直接调用该线程的 stop()来结束该线程(已过时)
记忆方式:
JDK5将就绪(Runnable)、运行 (Running)统一为了Runnable(可运行)
将阻塞(Blocked)细分为了Blocked(被阻塞)、Waiting(等待)、Timed Waiting(计时等待)
jdk1.5及其之后的6种状态
在java.lang.Thread.State 的枚举类中这样定义了6种状态:
NEW(新建):该线程还没开始执行
RUNNABLE(可运行):一旦调用start方法,线程将处于Runnable状态,一个可运行的线程可能正在运行也可能还未运行,这取决于操作系统给线程提供运行的时间。
- 一旦一个线程开始运行,它不必始终保持运行。(因为操作系统的时间片轮转机制,目的是让其他线程获得运行的机会)线程调度的细节依赖于操作系统提供的服务。抢占式调度系统给每一个可运行的线程一个时间片来执行任务。时间片完,操作系统将剥夺线程的运行权
注意:
任何给定时刻,一个可运行的线程可能正在运行也可能没有运行(这就是为什么将这个状态称为可运行而不是运行)
BLOCKED(被阻塞)
当线程处于被阻塞或等待状态时,它暂不活动。他不允许任何代码且消耗最少的资源。
WAITING(等待)
TIMED_WAITING(计时等待)
**TERMINATED(被终止)**线程被终止有如下两种原因:
- 因为run方法正常退出而自然死亡
- 因为一个没有捕获的异常终止了run方法而意外死亡
特点强调,可以调用线程的**stop()方法(已过时)**杀死这个线程,但是该方法会抛出ThreadDeath错误对象,由此杀死线程。
TIMED_WAITING(计时等待)
时间到 | ^ sleep()
interrupt | | 带有超时值的Object的wait
| | 带有超时值的Thread的join
| | LockSupport.parkNanos
| | LockSupport.parkUntil
| |
| | run()\main()正常结束
start() V | 异常结束
NEW(新建) ==================> RUNNABLE(可运行) ==================> RUNNABLE(死亡)
^ | ^|--------------------
| | |----------------| |
| | | |
获得监视器锁对象 | | synchornized | |
| | Lock | | 不带有超时值的Object的wait
| | | | 不带有超时值的Thread的join
| | notify()\notifyAll()| | Condition的await
| | join的线程结束 | | LockSupport.park
| | Condition的signal | |
| | LockSupport的unpark等许可| |
V | interrupt | |
BLOCKED(锁阻塞) | |
| |
| |
| |
| V
WAITING(无限等待)在java.lang.Thread.State 的枚举类中这样定义:
public enum State {
/**
* Thread state for a thread which has not yet started.
线程状态为尚未启动的线程。
*/
NEW, // NEW(新建):线程刚被创建,但是并未启动。还没调用 start 方法。
/**
* Thread state for a runnable thread. A thread in the runnable
* state is executing in the Java virtual machine but it may
* be waiting for other resources from the operating system
* such as processor.
线程状态,用于可运行的线程。可运行的线程
状态在Java虚拟机中执行,但可能
正在等待操作系统的其他资源
如处理器。
*/
RUNNABLE, // RUNNABLE(可运行):这里没有区分就绪和运行状态。因为对于 Java 对象来说,只能标记为可运行,至于什么时候运行,不是 JVM 来控制的了,是 OS 来进行调度的,而且时间非常短暂,因此对于 Java 对象的状态来说,无法区分
// 重点说明,根据 Thread.State 的定义,阻塞状态分为三种:BLOCKED、WAITING、TIMED_WAITING
BLOCKED, // BLOCKED(锁阻塞):在 API 中的介绍为:一个正在阻塞、等待一个监视器锁(锁对象)的线程处于这一状态。只有获得锁对象的线程才能有执行机会。
WAITING, // WAITING(无限等待):在 API 中介绍为:一个正在无限期等待另一个线程执行一个特别的(唤醒)动作的线程处于这一状态。
// 当前线程执行过程中遇到遇到 Object 类的 wait,Thread 类的join,LockSupport 类的 park 方法,并且在调用这些方法时,没有指定时间,那么当前线程会进入 WAITING 状态,直到被唤醒。
// 通过 Object 类的 wait 进入 WAITING 状态的要有 Object 的notify/notifyAll 唤醒;
// 通过 Condition 的 await 进入 WAITING 状态的要有Condition 的 signal 方法唤醒;
// 通过 LockSupport 类的 park 方法进入 WAITING 状态的要有LockSupport类的 unpark 方法唤醒
// 通过 Thread 类的 join 进入 WAITING 状态,只有调用join方法的线程对象结束才能让当前线程恢复
TIMED_WAITING, // TIMED_WAITING(计时等待):在 API 中的介绍为:一个正在限时等待另一个线程执行一个(唤醒)动作的线程处于这一状态。
// 当前线程执行过程中遇到 Thread 类的 sleep 或 join,Object 类的 wait,LockSupport 类的 park 方法,并且在调用这些方法时,设置了时间,那么当前线程会进入 TIMED_WAITING,直到时间到,或被中断
/**
* Thread state for a terminated thread.
* The thread has completed execution.
*/
TERMINATED; // Teminated(被终止):表明此线程已经结束生命周期,终止运行。
}说明:
当从 WAITING 或 TIMED_WAITING 恢复到 Runnable 状态时,如果发现当前线程没有得到监视器锁,那么会立刻转入 BLOCKED 状态
Java的线程优先级是什么?有什么用?
在Java中,每个线程都有一个优先级,优先级决定了线程调度器对线程的调度顺序。线程的优先级是一个整数值,范围在1到10之间。
Java 中的线程优先级用于指示线程调度器(Thread Scheduler)在分配 CPU 时间时对不同线程的重视程度。线程优先级是一个整数值,范围从 1 到 10,默认情况下所有线程的优先级为 5(即 NORM_PRIORITY)。优先级越高,线程越有可能被优先执行。
优先级常量
Java 提供了三个静态常量来表示常见的优先级:
MIN_PRIORITY:最低优先级,值为 1。
NORM_PRIORITY:默认优先级,值为 5。
MAX_PRIORITY:最高优先级,值为 10。
线程优先级的作用
口语化:线程优先级是对线程调度器的一种建议,调度器会根据优先级来决定哪个线程应该优先执行。然而,线程优先级并不能保证线程一定会按照优先级顺序执行,具体的调度行为依赖于操作系统的线程调度策略。
- 影响调度顺序:优先级较高的线程更有可能被调度器选中执行。然而,这并不意味着高优先级线程一定会立即执行,具体行为取决于操作系统的调度策略。
- 资源分配:在某些操作系统上,线程优先级可以影响 CPU 时间片的分配。高优先级线程可能会获得更多的 CPU 时间片,从而更快完成任务。
- 提高响应性:对于需要快速响应的任务(如用户界面事件处理),可以适当提高其优先级以确保及时处理。
- 避免饥饿:如果某些线程的优先级过低,可能会导致它们长时间得不到执行机会(即“饥饿”现象)。合理设置优先级可以避免这种情况。
设置线程优先级
可以通过setPriority(int newPriority)方法来设置线程的优先级。需要注意的是,设置的优先级必须在1到10之间,否则会抛出IllegalArgumentException
public class ThreadPriorityExample {
public static void main(String[] args) {
Thread lowPriorityThread = new Thread(() -> {
for (int i = 0; i < 5; i++) {
System.out.println("Low priority thread running");
}
});
lowPriorityThread.setPriority(Thread.MIN_PRIORITY);
Thread highPriorityThread = new Thread(() -> {
for (int i = 0; i < 5; i++) {
System.out.println("High priority thread running");
}
});
highPriorityThread.setPriority(Thread.MAX_PRIORITY);
lowPriorityThread.start();
highPriorityThread.start();
}
}我们创建了两个线程,一个设置为最低优先级,一个设置为最高优先级。通常情况下,系统会优先调度高优先级的线程执行,但这并不是绝对的,具体行为依赖于操作系统的调度策略。
注意事项
不可过度依赖优先级:线程优先级只是一个提示,具体的调度行为仍然由操作系统决定。不要完全依赖优先级来控制程序的行为,尤其是在跨平台应用中,不同操作系统的调度策略可能有所不同。
避免频繁调整优先级:频繁调整线程优先级可能会导致性能问题,并且难以预测实际效果。通常只在必要时进行调整。应该更多地通过设计合理的并发控制机制(如锁、信号量、条件变量等)来管理线程。
主调用栈限制:Java 规范要求主线程(main thread)的优先级不能低于其他线程。因此,设置线程优先级时需要注意这一点。
守护线程不受影响:守护线程(Daemon Thread)的优先级设置与普通线程相同,但它们不会影响 JVM 的退出行为。
join方法有什么用?什么原理?
join方法是Thread类中一个非常重要的方法,用于控制线程的顺序执行。
join 方法的作用
等待线程完成:
- 当一个线程调用另一个线程的
join方法时,当前线程会被阻塞,直到被调用的线程执行完毕。 - 这在需要确保某些操作顺序执行的情况下非常有用。
- 当一个线程调用另一个线程的
控制程序执行顺序:
- 通过使用
join方法,可以确保某些线程在其他线程完成之前不会继续执行,从而实现对程序执行顺序的控制。
- 通过使用
join 方法的原理
join方法的原理是通过调用 wait 方法来实现的。
线程同步机制:
join方法本质上是一种线程同步机制,它通过让当前线程进入等待状态来实现线程间的协调。- 当一个线程调用另一个线程的
join方法时,它会检查目标线程的状态(通过isAlive()方法)。如果目标线程已经完成,则立即返回;否则,当前线程会被阻塞,直到目标线程完成。
超时机制:
join方法还支持设置超时时间。例如,thread.join(timeout),其中timeout是一个以秒为单位的时间值。- 如果在指定的时间内目标线程没有完成,当前线程会自动恢复执行,而不必一直等待。
源码如下:
public final synchronized void join(long millis)
throws InterruptedException {
long base = System.currentTimeMillis();
long now = 0;
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (millis == 0) {
while (isAlive()) {
wait(0);
}
} else {
while (isAlive()) {
long delay = millis - now;
if (delay <= 0) {
break;
}
wait(delay);
now = System.currentTimeMillis() - base;
}
}
}怎么让3个线程按顺序执行?
- 使用join方法
- 使用CountDownLatch
- 使用CyclicBarrier
- 单个线程的线程池
Java中如何控制多个线程的执行顺序?
CompletableFuture,例如thenRun,假设t1、t2、t3任务要按顺序执行,就可以使用thenRun方法
synchronized + wait/notify,通过对象锁和线程间通信机制来控制线程的执行顺序
ReentrantLock + condition
Thread类的join方法,通过调用这个方法,可以使得一个线程等待另一个线程执行完毕后再继续执行
CountDownLatch,使一个或线程等待其他线程完成各自工作后再继续执行
CyclicBarrier,是多个线程互相等待,直到所有线程都到达某个共同点后再继续执行
Semaphore,控制线程的执行顺序,适用于需要限制同时访问资源的线程数量的场景
线程池,单个线程的线程池,按序的将任务提交到线程池即可
方式一:使用join方法
原理:
join方法可以让当前线程等待另一个线程执行完毕后再继续执行。- 通过依次调用线程的
join方法,可以确保线程按顺序执行
public class Main {
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
System.out.println("Thread 1 is running");
});
Thread t2 = new Thread(() -> {
try {
t1.join(); // 等待t1线程执行完毕
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread 2 is running");
});
Thread t3 = new Thread(() -> {
try {
t2.join(); // 等待t2线程执行完毕
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread 3 is running");
});
t1.start();
t2.start();
t3.start();
}
}方式二:使用CountDownLatch
原理:
CountDownLatch是一个同步工具类,允许一个或多个线程等待其他线程完成操作。- 初始化时设置计数器值,每个线程完成任务后调用
countDown减少计数器,当计数器为 0 时,等待的线程被唤醒。
public class Main {
public static void main(String[] args) {
CountDownLatch latch1 = new CountDownLatch(1);
CountDownLatch latch2 = new CountDownLatch(1);
Thread t1 = new Thread(() -> {
System.out.println("Thread 1 is running");
latch1.countDown(); // 线程t1执行完毕,计数器减1,通知t2线程开始执行
});
Thread t2 = new Thread(() -> {
try {
latch1.await(); // 等待t1线程执行完毕
System.out.println("Thread 2 is running");
latch2.countDown(); // 线程t2执行完毕,计数器减1,通知t3线程开始执行
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
Thread t3 = new Thread(() -> {
try {
latch2.await(); // 等待t2线程执行完毕
System.out.println("Thread 3 is running");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
t1.start();
t2.start();
t3.start();
}
}方式三:使用CyclicBarrier
CyclicBarrier是一个同步工具类,允许多个线程在某个屏障点(barrier point)相互等待。- 初始化时设置参与线程的数量,所有线程到达屏障点后才能继续执行
public class Main {
public static void main(String[] args) {
CyclicBarrier barrier1 = new CyclicBarrier(2);
CyclicBarrier barrier2 = new CyclicBarrier(2);
Thread t1 = new Thread(() -> {
System.out.println("Thread 1 is running");
try {
barrier1.await();
} catch (InterruptedException | BrokenBarrierException e) {
throw new RuntimeException(e);
}
});
Thread t2 = new Thread(() -> {
try {
barrier1.await();
System.out.println("Thread 2 is running");
barrier2.await();
} catch (InterruptedException | BrokenBarrierException e) {
throw new RuntimeException(e);
}
});
Thread t3 = new Thread(() -> {
try {
barrier2.await();
} catch (InterruptedException | BrokenBarrierException e) {
throw new RuntimeException(e);
}
System.out.println("Thread 3 is running");
});
t1.start();
t2.start();
t3.start();
}
}线程间的通信方式?
JVM的线程调度是什么?
线程调度是指 JVM 如何管理和分配 CPU 时间给各个线程。线程调度策略直接影响到多线程程序的性能和响应性。JVM 的线程调度主要依赖于底层操作系统的线程调度机制。
线程调度的基本概念
线程调度是指 JVM 选择某个线程来获得 CPU 时间片的过程。分为两种类型:
抢占式调度:操作系统根据线程的优先级和其他因素,强制中断正在运行的线程,并将 CPU 分配给另一个线程。
协作式调度:线程主动放弃 CPU 使用权,操作系统不会强制中断线程。
通常使用抢占式调度。
线程调度策略
- 时间片轮转
在时间片轮转调度策略中,每个线程按顺序获得一个固定长度的时间片,当时间片用完时,调度器将 CPU 分配给下一个线程。这种方式确保每个线程都有机会运行。
- 优先级调度
在优先级调度策略中,调度器优先选择高优先级线程运行。如果有多个同等优先级的线程,则使用时间片轮转策略。
常见的线程调度问题
- 线程饥饿
线程饥饿发生在低优先级线程长时间得不到 CPU 时间片的情况下。这可能是由于高优先级线程频繁占用 CPU 资源所致。
- 活锁
活锁类似于死锁,但线程并未真正阻塞,而是不断地改变状态,无法继续执行。活锁通常发生在线程频繁响应彼此的动作时。
线程调度优化
合理设置线程优先级:避免所有线程都设置为最高优先级,合理分配优先级以避免饥饿问题。
减少锁竞争:尽量减少线程之间的锁竞争,使用更细粒度的锁或无锁数据结构。
使用线程池:通过java.util.concurrent包中的线程池来管理线程,避免频繁创建和销毁线程带来的开销。
引起CPU进行上下文切换的原因
CPU 上下文切换是指 CPU 从一个进程或线程切换到另一个进程或线程的过程。
上下文切换涉及保存当前进程或线程的状态,并加载即将运行的进程或线程的状态。
上下文切换是多任务操作系统中实现并发的重要机制,但频繁的上下文切换会带来性能开销。
时间片耗尽
在抢占式多任务操作系统中,每个进程或线程都被分配一个固定长度的时间片。当时间片耗尽时,操作系统会进行上下文切换,将 CPU 分配给下一个进程或线程。
阻塞操作
当一个进程或线程执行阻塞操作(如 I/O 操作、等待锁、等待资源等)时,它会进入阻塞状态,操作系统会进行上下文切换,将 CPU 分配给其他可以运行的进程或线程。
进程或线程的优先级变化
操作系统调度程序会根据进程或线程的优先级进行调度。如果一个高优先级的进程或线程进入就绪状态,操作系统可能会进行上下文切换,将 CPU 分配给这个高优先级的进程或线程。
中断
硬件中断(如定时器中断、I/O 中断等)也会触发上下文切换。当中断发生时,操作系统会暂停当前进程或线程的执行,处理中断请求,然后可能会切换到另一个进程或线程。
补充:Java中中断机制是一种协作机制,这里指的是操作系统层面的中断
系统调用
当进程或线程执行系统调用时,可能会引发上下文切换。例如,当进程请求操作系统服务(如文件操作、网络操作等)时,操作系统可能会切换到内核态进行处理,然后再切换回用户态。
多处理器环境中的负载均衡
在多处理器或多核系统中,操作系统可能会进行上下文切换以实现负载均衡。操作系统会将进程或线程分配到不同的 CPU 核心,以优化资源利用率和性能。
线程调度策略
不同的线程调度策略(如时间片轮转、优先级调度等)会导致上下文切换。例如,在时间片轮转调度策略中,每个线程按顺序获得 CPU 时间片,当时间片用完时,操作系统会进行上下文切换。
用户态和内核态切换
当进程或线程从用户态切换到内核态(例如执行系统调用)或从内核态切换回用户态时,也会发生上下文切换。这种切换涉及保存和恢复 CPU 寄存器等状态。
上下文切换的开销
上下文切换虽然是多任务操作系统实现并发的必要机制,但它也带来了性能开销,主要包括:
CPU 寄存器保存和恢复:需要保存当前进程或线程的 CPU 寄存器状态,并加载下一个进程或线程的 CPU 寄存器状态。
内存管理:需要切换内存管理单元(MMU)的上下文,例如页表的切换。
缓存失效:上下文切换可能导致 CPU 缓存失效,从而影响性能。
优化上下文切换
减少线程数量:避免创建过多的线程,合理使用线程池。
减少锁竞争:使用无锁数据结构或更细粒度的锁,减少线程间的锁竞争。
优化调度策略:根据应用场景选择合适的调度策略,避免不必要的优先级切换。
使用异步 I/O:尽量使用异步 I/O 操作,减少阻塞操作引起的上下文切换
线程什么时候主动放弃CPU
线程主动放弃 CPU常见的有以下几种方式
- 调用Thread.yield()方法
- 调用Thread.sleep(long millis)方法
- 调用Object.wait()方法
- 调用Thread.join()方法
- 调用LockSupport.park()方法
Thread.yield()
Thread.yield()是一个静态方法,通知调度器当前线程愿意放弃 CPU 使用权,让其他同优先级或更高优先级的线程有机会运行。它只是一个提示,操作系统可以选择忽略这个提示。
场景
调试和性能优化:在某些情况下,yield()可以用于调试和性能优化,帮助识别线程调度问题。
避免资源独占:在某些高优先级的任务中,使用yield()可以避免线程长时间独占 CPU,稍微改善系统响应时间。
Thread.sleep(long millis)
Thread.sleep(long millis)使当前线程进入休眠状态,暂停执行指定的毫秒数。休眠期间,线程保持 CPU 使用权,但不执行任何代码。
场景
- 定时任务:在需要定时执行任务的场景中,sleep()可以用于实现简单的定时等待。
- 模拟延迟:在测试和模拟场景中,sleep()可以用于模拟网络延迟或其他等待时间。
Object.wait()
Object.wait()使当前线程等待(阻塞),直到其他线程调用notify()或notifyAll()方法唤醒它。wait()必须在同步块或同步方法中调用。
场景
- 线程间通信:在生产者-消费者模型中,wait()和notify()用于协调生产者和消费者线程之间的工作
public class WaitNotifyExample {
private static final Object lock = new Object();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
synchronized (lock) {
try {
System.out.println(Thread.currentThread().getName() + " is waiting");
lock.wait();
System.out.println(Thread.currentThread().getName() + " is resumed");
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}, "Thread-1");
Thread t2 = new Thread(() -> {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + " is notifying");
lock.notify();
}
}, "Thread-2");
t1.start();
try {
Thread.sleep(1000); // 确保 t1 先执行
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
t2.start();
}
}Thread.join()
Thread.join()使当前线程等待,直到另一个线程执行完毕。可以指定等待时间,也可以无限期等待。
场景
- 线程协调:在需要确保某些线程在其他线程之前完成时,使用join()来协调线程的执行顺序。
LockSupport.park()
LockSupport.park()使当前线程阻塞,直到被其他线程通过LockSupport.unpark(thread)唤醒。park()不会释放线程持有的锁,但可以响应中断。
补充:
调用LockSupport.park()不会阻塞线程的情况,就是调用LockSupport.park()方法进行阻塞之前,其他线程先调用了
LockSupport.unpark(thread),为该线程提前颁发了许可凭证
场景
- 线程控制:在需要精细控制线程行为的场景中,park()和unpark()提供了更底层和灵活的线程控制机制。
import java.util.concurrent.locks.LockSupport;
public class LockSupportExample {
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " is going to park.");
LockSupport.park();
System.out.println(Thread.currentThread().getName() + " has been unparked.");
}, "Thread-1");
t1.start();
try {
Thread.sleep(3000); // 让线程运行3秒
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
System.out.println("Unparking Thread-1.");
LockSupport.unpark(t1); // 唤醒线程
}
}sleep和wait的主要区别?
sleep和wait都是可以让线程暂停执行,但他们有明显的区别
使用方式不同
- wait方法必须在synchronize同步块或同步方法内调用,否则会抛出
IlleageMonitorStateException异常。- 这是因为wait依赖于对象锁来管理线程的等待和唤醒机制。
- sleep方法可以在任何上下文中调用,不需要获取对象锁。调用后,线程会进入休眠状态
锁状态不同
- wait方法调用后,当前线程会释放掉它所持有的对象锁,并进入等待状态
- sleep方法调用后,线程会进入休眠状态,但不会释放它所持有的任何锁
方法所属类不同
- wait方法属于Object类
- sleep方法属于Thread类,是静态方法
恢复方式不同
- wait方法:需要被其他线程调用notify或notifyAll 显示唤醒,或被wait(long time)的超时时间参数唤醒
- sleep方法:在指定的时间后,自行恢复运行,或通过抛出
InterruptedException恢复
用途不同
- wait方法:通常用于线程间通信,配合notify或notifyAll 来实现线程的协调工作
- sleep方法:用于让线程暂停执行一段时间,通常用于控制线程的执行频率或模拟延时、定时器等
扩展——常见错误
- 误用sleep:有时候开发者会错误使用sleep进行线程间通信,但是sleep不释放锁,可能会导致其他线程无法进入同步块,造成线程饥饿或死锁
- 忽略中断:sleep可能会抛出
InterruptedException(即线程中断状态标志位为true时),如果不正确处理中断信号,可能会导致线程提前退出或错误行为。- 原因:当中断状态为true时,sleep会抛出
InterruptedException,中断状态会被清除为false,因此需要显式的在catch中重新设置中断状态为true
- 原因:当中断状态为true时,sleep会抛出
sleep和wait、yield方法有什么区别?
Thread.sleep
sleep是Thead类中的静态方法,用于让当前线程睡眠,进入阻塞状态。
作用:使当前正在执行的线程暂停执行指定的时间(以毫秒为单位),让出 CPU 给其他线程。
特点:
- 不释放锁(即如果当前线程持有某个对象的同步锁,在睡眠期间不会释放该锁)。
- 必须捕获 InterruptedException 异常,因为当另一个线程中断了正在睡眠的线程时会抛出此异常。
适用场景:用于实现定时任务或需要线程暂停一段时间后再继续执行的情况。
try {
Thread.sleep(1000); // 线程暂停1秒
} catch (InterruptedException e) {
e.printStackTrace();
}Object.wait
wait是Object类中的实例方法,必须由同步锁对象调用(这一点是与其他方法最大的不同),用于让当前线程睡眠,进入阻塞状态。
- 作用:使当前线程等待,直到另一个线程调用同一个对象上的 notify() 或 notifyAll() 方法唤醒它。
- 特点:
- 必须在同步代码块中调用(即必须获取对象的锁后才能调用 wait 方法),并且会释放锁(对象锁)。
- 可以指定等待时间,超时后自动唤醒;如果不指定时间,则一直等待直到被唤醒。
- 同样需要处理 InterruptedException 异常。
- 适用场景:通常用于线程间通信,比如生产者-消费者模式。
public class WaitNotifyExample {
private static final Object lock = new Object();
public static void main(String[] args) {
Thread waitingThread = new Thread(() -> {
synchronized (lock) {
try {
System.out.println("Thread is waiting");
lock.wait(); // 进入等待状态,并释放锁
System.out.println("Thread is resumed");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread notifyingThread = new Thread(() -> {
synchronized (lock) {
try {
Thread.sleep(2000); // 休眠2秒
System.out.println("Thread is going to notify");
lock.notify(); // 唤醒等待线程
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
waitingThread.start();
notifyingThread.start();
}
}Thread.yield
yield是Thead类中的静态方法,用于让当前线程暂停执行,让出CPU,进入就绪状态。
- 作用:提示当前线程让出 CPU 占用时间,给其他同优先级的线程以执行的机会。
- 特点:
- 不保证当前线程会立即让出 CPU,也不保证其他线程会立即得到执行机会。
- 不会抛出异常,也不需要在同步上下文中使用。
- 不释放任何锁资源。
- 适用场景:用于希望多个同优先级的线程能够更加“公平”地获得 CPU 时间,但实际效果依赖于 JVM 和操作系统的线程调度策略。
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5; i++) {
System.out.println("Thread 1: " + i);
if (i == 2) Thread.yield(); // 尝试让出CPU
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5; i++) {
System.out.println("Thread 2: " + i);
}
});
t1.start();
t2.start();
}| Thread.sleep | object.wait | Thread.yield | |
|---|---|---|---|
| 定义 | Thread.sleep(long millis)是一个静态方法 | wait()是一个实例方法,属于Object类 | Thread.yield()是一个静态方法 |
| 作用 | 使当前线程进入休眠状态,暂停执行一段时间(以毫秒为单位) | 使当前线程等待,直到另一个线程调用该对象的notify()或notifyAll()方法来唤醒它。 | 提示当前线程让出 CPU 占用时间,给其他同优先级的线程以执行的机会。 |
| 锁状态 | 不释放锁:当前线程在睡眠期间仍然持有它所获取的任何锁 | 释放锁:必须在同步代码块或方法中调用 wait(),并且会立即释放对象的锁。等待被唤醒后重新竞争锁 | 不释放锁:让出 CPU 时不释放任何锁资源。 |
| 唤醒 | 自动唤醒:指定的时间到了之后自动恢复执行,无需其他线程干预 | 需要显式唤醒: 可以通过调用同一个对象上的 notify() 或 notifyAll() 方法来唤醒等待中的线程。 如果指定了超时时间(如 wait(long timeout)),则超时后也会自动唤醒。 Thr | 无唤醒机制:只是一个提示,线程调度器可能会选择其他线程运行,但没有明确的唤醒机制。 |
| 异常 | 抛出 InterruptedException:如果在睡眠期间线程被中断,则会抛出此异常。因此,调用 sleep 的代码通常需要捕获并处理这个异常 | 抛出 InterruptedException:同样地,如果在等待期间线程被中断,则会抛出此异常。此外,wait 必须在同步上下文中使用,否则会抛出 IllegalMonitorStateException。 | 不抛出异常:不会抛出任何异常,也不需要特别的异常处理 |
| 场景 | 定时任务:适用于需要线程暂停一段时间后再继续执行的情况,例如模拟延迟、实现定时器等。 避免忙等待:用于减少不必要的 CPU 占用,比如在轮询机制中引入适当的休眠时间。 | 线程间通信:适用于生产者-消费者模式、多线程协作等场景,其中一个线程需要等待另一个线程完成某些工作。 条件变量:用于实现更复杂的线程同步逻辑,确保某个条件满足时再继续执行。 | 同优先级线程调度:适用于希望多个同优先级的线程能够更加“公平”地获得 CPU 时间的情况,但实际效果依赖于 JVM 和操作系统的线程调度策略。 提示性调度:由于其不可靠性,一般不建议作为主要的线程控制手段,更多是作为一种优化提示。 |
Thread.sleep(0)有意义吗?有什么用?
口语化
sleep方法的作用是让线程暂停执行,进入到阻塞状态,让出CPU的执行权,但他不会释放锁资源
这个方法的底层是调用操作系统的sleep或者是nanosleep系统调用,操作系统会把这个线程挂起,让出CPU的执行权给到其他线程或进程,同时操作系统会设置一个定时器,当定时器到了以后操作系统会再次唤醒这个线程。
Thread.sleep(0)虽然没有传递睡眠时长,但是它会触发线程调度的切换,也就是说当前线程会从运行状态变为就绪状态,然后操作系统的调度器会根据优先级来选择一个线程来执行。如果有优先级更高的线程正在等待CPU时间片,那么这个线程就会得到执行。如果没有,那么就会立即选择刚刚进入就绪状态的这个线程来执行 。具体的调度策略,取决于操作系统层面的调度算法。
Thread.sleep(0) 的行为
- 根据 Java 官方文档,
Thread.sleep(0)不会让线程暂停执行。 - 它的主要作用是提示调度器重新评估线程优先级并进行线程调度。
具体来说:
- 调用
Thread.sleep(0)会将当前线程的状态从“运行”切换为“可运行”,从而允许其他线程获得 CPU 时间。 - 这种行为类似于主动放弃当前时间片(time slice),但不会像
Thread.yield()那样严格依赖于线程优先级。
实际用途
虽然 Thread.sleep(0) 的使用场景较少,但在某些特定情况下仍然有意义:
强制线程调度
- 在多线程环境中,如果某个线程长时间占用 CPU,可能会导致其他线程得不到执行机会。
- 调用
Thread.sleep(0)可以主动让出 CPU 时间片,使调度器有机会选择其他线程运行。
调试和测试
- 在调试或测试多线程程序时,可以插入
Thread.sleep(0)来观察线程调度的行为。 - 它可以帮助开发者验证线程切换是否按预期发生。
- 在调试或测试多线程程序时,可以插入
避免忙等待(Busy Waiting)
- 在某些低级别的同步机制中,线程可能需要通过循环检测某个条件是否满足(即忙等待)。
- 调用
Thread.sleep(0)可以减少 CPU 占用,同时允许其他线程运行。
与 Thread.yield() 的区别
Thread.sleep(0):- 提示调度器重新评估线程优先级。
- 不依赖线程优先级,适用于所有线程。
Thread.yield():- 建议调度器将当前线程的时间片让给相同或更高优先级的线程。
- 行为依赖于线程优先级,且实现可能因 JVM 和操作系统而异。
性能影响
- 调用
Thread.sleep(0)的开销非常小,因为它不会真正阻塞线程。 - 然而,频繁调用可能会增加线程调度的开销,因此应谨慎使用。
总结
Thread.sleep(0)的主要作用是提示调度器重新评估线程优先级并进行线程切换。它的应用场景相对有限,但在调试、测试或优化线程调度时可能会用到。如果你的目标是显式地让出 CPU 时间片,建议优先考虑
Thread.yield()或更高级的同步机制(如锁或信号量)。
怎么理解Java中的线程中断(interrupt)?
口语化
首先,一个线程不应该由其他线程来强制中断或停止,而是应该由线程自己自行停止,自己来决定自己的命运。所以,Thread.stop、Thread.suspend、Thread.resume这几个方法都被废弃了。
其次,Java中没有办法立即停止一个线程,然而停止线程是一个非常重要的操作,例如取消一个耗时操作。
因此,Java提供了一种用于停止线程的协商机制——中断,也即中断标识协商机制。
中断只是一个协作协商机制,Java没有给中断增加任何语法,中断的过程完全需要我们自己手动实现。
若要中断一个线程,我们需要手动调用线程的interrupt方法,该方法也仅仅是将线程对象的中断标识设为为true
接着你需要手写代码不断地检测当前线程的标识位,如果为true,表示别的线程请求这个线程中断,此时究竟该做什么也需要我们自己手写代码实现。
每个线程对象都有一个中断标识位,用于表示线程是否被中断;该标识为为true表示中断,为false表示未中断;
通过调用线程对象的interrupt方法可以将该线程的标识为设置为true;可以在别的线程中调用,也可以在自己的线程中调用。
Java中的线程中断是一种协作机制,用于请求线程停止其所执行的任务。线程中断并不强制终止线程,而是通过设置线程的中断标志来通知一个正在运行的线程应该停止当前的任务并进行清理或终止。线程可以选择如何响应这个中断请求,通常是在合适的时机优雅地终止任务。
线程中断的核心概念
- 中断状态:每个线程都有一个中断状态(interrupted status),初始值为 false。当调用
线程.interrupt()方法时,该线程的中断状态被设置为 true。 - 检查中断状态:
线程.isInterrupted():检查当前线程的中断状态,但不会重置中断标志。Thread.interrupted():1、检查当前线程的中断状态 2、并重置中断标志为 false
- 响应中断:线程可以选择如何响应中断。通常的做法是在适当的地方检查中断状态,并根据需要执行清理操作或终止线程(手写代码实现)
中断线程三大API
| 方法 | 描述 |
|---|---|
| public void interrupt() | 实例方法。设置线程的中断状态为true,发起一个协商而不会立即停止线程 // Just to set the interrupt flag |
| public static boolean interrupted() | 静态方法。判断线程是否被中断并清除当前中断状态。 这个方法做了两件事情: 1、返回当前线程的中断状态 2、将当前的中断状态清零并重设为false,清理线程的中断状态 |
| public boolean isInterrupted() | 实例方法。判断当前线程是否已被中断 |
注意:
以下阻塞方法(如Thread.sleep()、Object.wait()、BlockingQueue.take()等)会在检测到中断标志时抛出InterruptedException异常,并重置中断状态
说人话就是,如果某个线程中使用了这些方法,且这些方法正在运行,此时线程的标志位为true时,就会抛出InterruptedException异常
线程中断的行为(即中断标志位为true时)
阻塞方法:如果线程正在执行阻塞方法(如
Thread.sleep()、Object.wait()、BlockingQueue.take()等),此时线程标志位被设置为true,会抛出InterruptedException,并在捕获到中断时清除中断状态(即中断状态会被设置为false,因此建议手动重新设置中断状态为true)。非阻塞代码:对于非阻塞代码,线程需要定期检查中断状态,并根据需要处理中断请求。
public class ThreadInterruptionExample {
public static void main(String[] args) throws InterruptedException {
// 创建并启动一个新线程
Thread worker = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
System.out.println("Working...");
try {
// 模拟长时间运行的任务
Thread.sleep(500);
} catch (InterruptedException e) {
// 捕获中断异常并设置中断状态
System.out.println("Thread was interrupted, stopping...");
Thread.currentThread().interrupt(); // 重新设置中断状态为true
return;
}
}
System.out.println("Thread is stopping gracefully...");
});
worker.start();
// 主线程等待一段时间后中断工作线程
Thread.sleep(2000);
System.out.println("Main thread is interrupting the worker thread...");
worker.interrupt();
// 等待工作线程结束
worker.join();
System.out.println("Worker thread has finished.");
}
}在这个例子中,创建了一个worker线程,在其whele循环中不断处理任务,直到检测到线程中断状态为true。
主线程会在2s后通过worker.interrupt()方法设置worker线程的中断状态为true。worker线程内部捕获到InterruptedException异常,会重新设置中断状态。因此需要在catch语句中设置状态状态为true
线程中断的最佳实践
- 礼貌中断:不要强制终止线程,而是通过中断机制让线程有机会进行清理和资源释放。
- 定期检查中断状态:在线程的长时间运行任务中,应定期检查中断状态,以确保能够及时响应中断请求。
- 处理阻塞方法:对于可能会抛出 InterruptedException 的阻塞方法,务必捕获异常并适当地处理。
- 重设中断状态:在捕获 InterruptedException 后,可以考虑重新设置中断状态,以便其他代码段也能感知到中断请求。
- 避免忽略中断:不要简单地忽略中断请求,应该根据业务逻辑合理处理。
为什么多线程执行时,需要catch InterruptedException异常,catch里面写啥
在多线程编程中,捕获InterruptedException是非常重要的,因为它是线程间通信的一种方式,用于通知线程应该停止当前的工作并尽快退出。
为什么需要捕获InterruptedException
线程中断机制:InterruptedException是 Java 提供的一种机制,用于中断线程的执行。当一个线程被其他线程中断时(通过调用interrupt()方法),如果该线程正在等待、睡眠或尝试获取锁,则会抛出InterruptedException
资源清理:捕获并处理InterruptedException可以确保在线程被中断时,进行必要的资源清理工作,以避免资源泄漏。
响应中断:捕获InterruptedException并适当地处理它,可以使线程更好地响应中断请求,遵循良好的线程中断协议。
在catch块中应该做什么
恢复中断状态:如果你不打算立即响应中断,可以在捕获InterruptedException后恢复线程的中断状态,以便上层调用者能够知道线程曾经被中断。
资源清理:在捕获异常后进行必要的资源清理,比如关闭文件、释放锁等。
退出线程:如果线程应该响应中断并退出,可以在捕获异常后适当地退出线程。
interrupt的标志位是否会回归到原有标记
当一个线程被中断时,其中断状态会被设置为true。然而,当InterruptedException被抛出时,中断状态会被清除,即标志位会被重置为false。如果你不显式地重新设置中断状态,其他代码将无法检测到这个中断。
class Worker implements Runnable {
@Override
public void run() {
try {
// 模拟阻塞操作,如 Thread.sleep 或 wait
Thread.sleep(2000);
} catch (InterruptedException e) {
// 捕获 InterruptedException 后,中断状态会被清除
System.out.println("Thread was interrupted: " + Thread.currentThread().isInterrupted()); // false
// 恢复中断状态
Thread.currentThread().interrupt();
System.out.println("Thread was interrupted: " + Thread.currentThread().isInterrupted()); // true
}
}
}
public class Main {
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new Worker());
thread.start();
Thread.sleep(1000); // 确保线程已经开始执行
thread.interrupt(); // 中断线程
}
}在这个示例中:
- Thread.sleep(2000)模拟一个阻塞操作。
- 当线程被中断时,会抛出InterruptedException,此时中断状态会被清除。
- 在catch块中,打印中断状态会显示false,因为中断状态已经被清除。
- 调用Thread.currentThread().interrupt()恢复中断状态。
- 再次打印中断状态,这次会显示true。
当InterruptedException被抛出时,中断状态会被清除。因此,如果你希望其他代码能够检测到线程曾经被中断,应该在catch块中显式地调用Thread.currentThread().interrupt()来恢复中断状态。这样可以确保线程间的中断通信能够正确进行,保持程序的健壮性和可维护性。
interrupt和stop有什么区别?
interrupt方法
interrupt方法用于让线程中断,是一种协作机制,用于请求线程停止其所执行的任务。线程中断并不强制终止线程,而是通过设置线程的中断标志来通知一个正在运行的线程应该停止当前的任务并进行清理或终止。线程可以选择如何响应这个中断请求,通常是在合适的时机优雅地终止任务。
特点
非强制性:线程可以选择是否响应中断请求。
中断状态:调用 interrupt() 会将线程的中断状态设置为 true。
阻塞方法interrupt()的行为:
- 如果线程在执行阻塞方法时(如 Thread.sleep()、Object.wait()、BlockingQueue.take() 等)中被中断,这些方法会抛出 InterruptedException 并清除中断状态。
- 如果线程没有处于阻塞状态,则需要手动检查中断状态并决定如何处理。
Thread thread = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
System.out.println("Working...");
try {
Thread.sleep(1000); // 模拟阻塞操作
} catch (InterruptedException e) {
System.out.println("Thread was interrupted, stopping...");
return; // 响应中断请求并退出
}
}
});
thread.start();
Thread.sleep(2000); // 主线程等待一段时间
thread.interrupt(); // 发送中断请求
thread.join(); // 线程线程结束才会结束主线程stop()方法
stop() 是一种强制终止线程的方法,直接停止线程的执行(直接进入死亡状态),并释放线程持有的所有锁。
特点
强制性:调用 stop() 会立即终止线程,无论线程当前正在做什么。
危险性:
- 可能导致资源泄漏(如文件未关闭、数据库连接未释放等)。run()即刻停止,可能会导致一些清理性的工作得不到完成,如文件,数据库等的关闭
- 可能导致数据不一致(如线程在更新共享数据时被强制终止)。
- 可能引发死锁问题(因为线程持有的锁会被突然释放)。
已废弃:由于上述问题,stop() 方法在 Java 早期版本中就被标记为不推荐使用(deprecated)。
Thread thread = new Thread(() -> {
while (true) {
System.out.println("Working...");
try {
Thread.sleep(1000); // 模拟阻塞操作
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread.start();
Thread.sleep(2000); // 主线程等待一段时间
thread.stop(); // 强制终止线程注意:虽然 stop() 方法仍然可以使用,但它已经被废弃,不应在现代 Java 程序中使用。
主要区别
| 特性 | interrupt() | stop() |
|---|---|---|
| 强制性 | 非强制性,线程可以选择是否响应 | 强制终止线程,释放线程持有的所有锁 |
| 安全性 | 安全,允许线程进行清理和资源释放 | 不安全,可能导致资源泄漏或数据不一致 |
| 中断状态 | 设置线程的中断状态为 true | 无中断状态的概念 |
| 阻塞方法的行为 | 抛出 InterruptedException 并清除状态 | 直接终止线程 |
| 推荐使用 | 推荐使用的线程终止方式 | 已废弃,不推荐 |
为什么推荐使用 interrupt() 而不是 stop()?
- 优雅退出:interrupt() 允许线程在合适的时间点退出,从而避免资源泄漏或数据不一致的问题。
- 可控性:线程可以决定如何响应中断请求,例如完成当前任务后再退出。
- 灵活性:可以通过定期检查中断状态来实现更复杂的线程控制逻辑
什么是LockSupport类?Park和unPark的使用
LockSupport 是用来创建锁和其他同步类的基本线程阻塞原语。
LockSupport 是 Java 并发包 (java.util.concurrent) 中的一个工具类,所有的方法都是静态方法,可以让线程在任意位置阻塞,阻塞之后也有对应的唤醒方法。
归根结底,LockSupport 调用的是 Unsafe 中的native 代码
LockSupport 提供 park 和 unpark 方法实现阻塞线程和解除线程阻塞的过程。
LockSupport 和每个使用它的线程都有一个许可(permit)关联
每个线程都有一个相关的permit,permit最多只有一个,重复调用unpark也不会积累凭证。
形象的理解
线程阻塞需要消耗凭证(permit),这个凭证最多只有一个
当调用park方法时
- 如果有凭证,则直接消耗掉这个凭证,然后正常退出
- 如果无凭证,就必须阻塞等待凭证可用
而unpark则相反,它会增加一个凭证,但凭证最多只能有1个,累加无效
LockSupport 的主要功能和特点:
阻塞线程:通过 LockSupport.park() 方法可以让当前线程阻塞。
唤醒线程:通过 LockSupport.unpark(Thread thread) 方法可以唤醒指定的线程。
轻量级:相比 Object.wait() 和 Object.notify(),LockSupport 提供了更灵活和细粒度的控制。
许可证机制:每个线程都有一个与之关联的“许可证”(permit)。
- 当调用
park()时,如果当前线程已经有许可证,则直接消耗许可证并继续执行;如果没有许可证,则线程会被阻塞,直到获得许可证。 - 调用
unpark()会为线程提供一个许可证(如果有多个未处理的unpark()调用,只会消耗一个)。
- 当调用
示例:
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t ---come in");
LockSupport.park();
System.out.println(Thread.currentThread().getName() + "\t ---被唤醒");
}, "t1");
t1.start();
try {
TimeUnit.SECONDS.sleep(2L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
new Thread(() -> {
LockSupport.unpark(t1);
System.out.println(Thread.currentThread().getName() + "\t ---发出通知");
}, "t2").start();
}补充
3种线程等待与唤醒的方法
1、Object类中的wait与notify方法
- wait和notify方法必要要在同步块或方法中使用,否则运行时抛出
IllegalMonitorStateException - 且wait顺序和notify顺序不能弄反
- 最好是成对出现使用
2、Condition接口中的await与signal方法
Condition中的线程等待和唤醒,需要先获取锁,否则运行时抛出
IllegalMonitorStateException且await顺序和signal顺序不能弄反
最好是成对出现使用
Object和Condition使用的限制条件
线程先要获得并持有锁,必须在锁块(synchronized 或 lock)在调用
必须要先等待后唤醒,线程才能够被唤醒,否则线程将一致被阻塞
- (即wait与notify、await与signal方法必须成双成对出现)
3、LockSupport类中的park与unpark方法
LockSupport是用来创建锁和其他同步类的基本线程阻塞原语
LockSupport类使用了一种名为Permit(许可)的概念来做到阻塞和唤醒线程的功能,每个线程都有一个Permit(许可)
但与 Semaphore 不同的是,许可的累加上限制是1
LockSupport的park/unpark为什么可以突破wait/notify的原有调用顺序?
因为unpark获取了一个凭证,之后再调用park方法,就可以名正言顺的凭证消费,故而不会阻塞。
可以理解为高速收费站的ETC
LockSupport的park/unpark为什么唤醒两次后阻塞两次,但最终结果还是会阻塞线程?
口语化
因为凭证的数量最多为1,不会累加。连续调用两次unpark和调用一次unpark的效果一样,只会增加一个凭证。
而调用两次park却需要消耗两个凭证,凭证不够,不能放行。
核心原因:许可证机制
- 每个线程有一个许可证:
- 每个线程都有一个与之关联的“许可证”。
- 调用
LockSupport.unpark(Thread thread)会为指定线程提供一个许可证。 - 调用
LockSupport.park()时,如果当前线程已经有许可证,则直接消耗许可证并继续执行;如果没有许可证,则线程会被阻塞,直到获得许可证。
- 许可证是一次性的:
- 许可证只能被使用一次。当线程调用
park()并成功获取许可证后,许可证会被消耗掉。 - 如果多次调用
unpark(),只会增加一个许可证(即使多次调用,也只记录一个许可证)。
- 许可证只能被使用一次。当线程调用
- 为什么最终还会阻塞?
- 假设你调用了两次
unpark,这相当于为线程准备了一个许可证。 - 当第一次调用
park()时,线程会消耗这个许可证并继续执行。 - 第二次调用
park()时,由于许可证已经被消耗完,线程将再次被阻塞。
- 假设你调用了两次
private static void lockSupportParkUnpark() {
Thread t1 = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t ---come in");
LockSupport.park();
System.out.println(Thread.currentThread().getName() + "\t ---come in 2");
LockSupport.park();
System.out.println(Thread.currentThread().getName() + "\t ---被唤醒");
}, "t1");
t1.start();
try {
TimeUnit.SECONDS.sleep(2L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
new Thread(() -> {
LockSupport.unpark(t1);
LockSupport.unpark(t1);
System.out.println(Thread.currentThread().getName() + "\t ---发出通知");
}, "t2").start();
}在这个例子中,两次调用了unpark,为t1线程颁发许可,但许可不累加,只有1个。最终t1线程调用了两次park,需要两个许可,但t1只有一个许可,最终导致线程阻塞
如何优雅的终止一个线程?
在 Java 中,优雅地终止一个线程意味着确保线程能够在合适的时间点安全退出,并且不会导致资源泄漏、数据不一致或其他问题。
常见方案:
- 使用 interrupt() 和循环检查中断状态
- 使用标志位控制线程的生命周期,例如volatile修饰的变量、原子类AtomicBoolean
- 使用 ExecutorService 进行线程管理
使用 interrupt() 和循环检查中断状态
这是最常见也是最推荐的方式。通过在循环中定期检查线程的中断状态,线程可以在接收到中断请求时安全退出。
public class GracefulShutdownExample {
public static void main(String[] args) throws InterruptedException {
Thread worker = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
try {
System.out.println("Working...");
Thread.sleep(500); // 模拟长时间运行的任务
} catch (InterruptedException e) {
System.out.println("Thread was interrupted, stopping...");
Thread.currentThread().interrupt(); // 重新设置中断状态
return;
}
}
System.out.println("Thread is stopping gracefully...");
});
worker.start();
Thread.sleep(2000); // 主线程等待一段时间后中断工作线程
System.out.println("Main thread is interrupting the worker thread...");
worker.interrupt();
// 等待工作线程结束
worker.join();
System.out.println("Worker thread has finished.");
}
}关键点
while (!Thread.currentThread().isInterrupted()):在循环中定期检查中断状态。
捕获 InterruptedException:如果线程在阻塞方法(如 Thread.sleep())中被中断,会抛出 InterruptedException,此时可以处理中断并退出。
重设中断状态:在捕获 InterruptedException 后,调用 Thread.currentThread().interrupt() 重新设置中断状态,以便其他代码段也能感知到中断请求。
使用标志位控制线程的生命周期
除了使用 interrupt(),还可以通过一个共享的标志位来控制线程的生命周期。
这种方式适用于需要更复杂的终止逻辑或不适合使用中断的场景。
示例:使用volatile修饰
public class FlagBasedShutdownExample {
private static volatile boolean running = true;
public static void main(String[] args) throws InterruptedException {
Thread worker = new Thread(() -> {
while (running) {
System.out.println("Working...");
try {
Thread.sleep(500); // 模拟长时间运行的任务
} catch (InterruptedException e) {
System.out.println("Thread was interrupted, stopping...");
return;
}
}
System.out.println("Thread is stopping gracefully...");
});
worker.start();
Thread.sleep(2000); // 主线程等待一段时间后停止工作线程
System.out.println("Main thread is stopping the worker thread...");
running = false;
// 等待工作线程结束
worker.join();
System.out.println("Worker thread has finished.");
}
}关键点
- volatile 标志位:使用 volatile 关键字确保标志位的可见性,避免线程缓存导致的问题。
- 标志位控制:通过外部控制标志位 running 来决定线程是否继续执行。
使用 ExecutorService 进行线程管理
现代 Java 编程中,推荐使用 ExecutorService 来管理线程池和任务提交。ExecutorService 提供了更高级的线程管理和优雅终止机制。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class ExecutorServiceShutdownExample {
public static void main(String[] args) throws InterruptedException {
ExecutorService executor = Executors.newSingleThreadExecutor();
// 提交任务
executor.submit(() -> {
while (!Thread.currentThread().isInterrupted()) {
System.out.println("Working...");
try {
Thread.sleep(500); // 模拟长时间运行的任务
} catch (InterruptedException e) {
System.out.println("Task was interrupted, stopping...");
return;
}
}
});
// 等待一段时间后关闭线程池
Thread.sleep(2000);
System.out.println("Shutting down executor service...");
// 发送关闭请求
executor.shutdown();
// 等待所有任务完成或超时
if (!executor.awaitTermination(1, TimeUnit.SECONDS)) {
System.out.println("Tasks did not complete in time, forcing shutdown...");
executor.shutdownNow(); // 强制终止未完成的任务
}
System.out.println("Executor service has been shut down.");
}
}关键点
- shutdown():发送关闭请求,不再接受新任务,但允许正在执行的任务完成。
- awaitTermination():等待所有任务完成,或在指定时间内超时。
- shutdownNow():强制终止所有正在执行的任务,并返回未执行的任务列表。
如何判断代码是不是有线程安全问题?如何解决
识别共享资源
关键点
- 共享变量:多个线程访问同一个变量(尤其是可变变量)时,可能会引发竞争条件。
- 共享对象:多个线程操作同一个对象实例,尤其是该对象包含可变状态时,需要特别注意。
public class Counter {
private int count = 0;
public void increment() {
count++; // 可能存在线程安全问题
}
public int getCount() {
return count;
}
}在这个例子中,count++ 操作不是原子性的,可能会导致多个线程同时修改 count,从而产生错误的结果。
检查同步机制
关键点
- 同步块:使用 synchronized 关键字来确保同一时刻只有一个线程可以执行特定代码段。
- 锁机制:使用显式的锁(如 ReentrantLock)来控制对共享资源的访问。
- 原子类:使用 java.util.concurrent.atomic 包中的原子类(如 AtomicInteger)来避免显式同步。
改进后的示例
import java.util.concurrent.atomic.AtomicInteger;
public class ThreadSafeCounter {
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet(); // 线程安全的增量操作
}
public int getCount() {
return count.get();
}
}查找竞争条件
关键点
- 临界区:多个线程同时访问共享资源的代码段称为临界区。如果临界区没有适当的同步机制,可能会导致竞争条件。
- 双重检查锁定:在某些情况下,双重检查锁定可能导致线程安全问题,尤其是在处理单例模式时。
示例代码(存在竞争条件)
public class Singleton {
private static Singleton instance;
public static Singleton getInstance() {
if (instance == null) { // 第一次检查
synchronized (Singleton.class) {
if (instance == null) { // 第二次检查
instance = new Singleton(); // 可能存在线程安全问题
}
}
}
return instance;
}
}在这个例子中,虽然使用了双重检查锁定,但如果 new Singleton() 的构造过程被中断,可能会导致部分初始化的问题。
改进后的示例代码(使用静态内部类)
public class Singleton {
private Singleton() {}
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return SingletonHolder.INSTANCE; // 线程安全的单例模式
}
}在这个改进版本中,静态内部类确保了单例的线程安全性。
分析死锁可能性
关键点
- 锁顺序:多个线程获取锁的顺序不一致可能会导致死锁。确保所有线程以相同的顺序获取锁。
- 嵌套锁:避免在一个线程中嵌套获取多个锁,这会增加死锁的风险。
示例代码(潜在死锁)
public class DeadlockExample {
private final Object lock1 = new Object();
private final Object lock2 = new Object();
public void method1() {
synchronized (lock1) {
synchronized (lock2) {
// 执行任务
}
}
}
public void method2() {
synchronized (lock2) {
synchronized (lock1) {
// 执行任务
}
}
}
}在这个例子中,method1 和 method2 获取锁的顺序不同,可能会导致死锁。
改进后的示例代码(统一锁顺序)
public class DeadlockFreeExample {
private final Object lock1 = new Object();
private final Object lock2 = new Object();
public void method1() {
synchronized (lock1) {
synchronized (lock2) {
// 执行任务
}
}
}
public void method2() {
synchronized (lock1) { // 统一锁顺序
synchronized (lock2) {
// 执行任务
}
}
}
}使用工具和测试
关键点
- 静态分析工具:使用静态分析工具(如 FindBugs、PMD、SonarQube)可以帮助自动检测潜在的线程安全问题。
- 单元测试:编写多线程单元测试(如 JUnit + MultithreadedTC)来验证代码在并发环境下的行为。
- 性能监控:使用性能监控工具(如 VisualVM、JProfiler)来观察线程的行为和资源争用情况。
示例工具
- FindBugs:可以检测常见的线程安全问题,如未同步的共享变量。
- JUnit + MultithreadedTC:用于编写多线程测试用例,模拟并发场景。
- VisualVM:用于监控线程的状态和资源使用情况。
遵循最佳实践
- 不可变对象:尽量使用不可变对象(如 final 字段、不可变集合),因为它们天生是线程安全的。
- 局部变量:优先使用局部变量而不是共享变量,因为局部变量是线程私有的。
- 最小化锁范围:尽量缩小同步块的范围,减少锁的持有时间,提高并发性能。
- 使用并发工具类:充分利用 java.util.concurrent 包中的工具类(如 ConcurrentHashMap、CopyOnWriteArrayList)来简化线程安全的实现。
总结
要判断代码是否存在线程安全问题,可以通过以下步骤进行:
- 识别共享资源:找出哪些变量或对象可能被多个线程访问。
- 检查同步机制:确保对共享资源的访问有适当的同步机制。
- 查找竞争条件:分析代码中是否存在可能导致竞争条件的临界区。
- 分析死锁可能性:确保锁的获取顺序一致,避免死锁。
- 使用工具和测试:利用静态分析工具和多线程测试来验证代码的安全性。
- 遵循最佳实践:尽量使用不可变对象、局部变量和并发工具类来简化线程安全的实现。
wait和notifiy的虚假唤醒的产生原因及如何解决
怎么理解wait、notify、notifyAll方法?
wait、notify、notifyAll是Java中用于线程间通信的重要方法,它们都定义在Object类中。这些方法主要用于协调多个线程对共享资源的访问,确保线程之间的正确同步,主要用于解决生产者与消费者问题,它们的搭配使用我们也成为等待与唤醒机制。
- wait():使当前线程进入等待状态,并释放当前对象的锁,直到其他线程调用该对象上的 notify() 或 notifyAll() 方法唤醒它。
- notify():唤醒一个正在等待该对象监视器的单个线程(如果有多个线程等待被唤醒,具体哪个线程由 JVM 决定)
- notifyAll():唤醒所有正在等待该对象监视器的线程。被唤醒的线程会重新竞争锁,但最终只有一个线程能够获取锁并继续执行。
这三个方法都必须在同步上下文中调用,即必须在 synchronized 块或方法中使用。否则,会抛出 IllegalMonitorStateException 异常。
在JUC中,也有一组类似的方法,Condition的signal(唤醒)、await
注意事项
- 必须在同步上下文中调用
- wait()、notify() 和 notifyAll() 必须在 synchronized 块或方法中调用,因为它们依赖于对象的监视器锁。如果不在同步上下文中调用,会导致 IllegalMonitorStateException。
// 正确的用法
synchronized (obj) {
obj.wait(); // 在同步块中调用
}
// 错误的用法
obj.wait(); // 不在同步块中调用,会抛出异常- 避免忙等
- 不要在循环外直接调用 wait(),而应该使用 while 循环来检查条件是否满足。这是因为当线程被唤醒时,条件可能仍然不满足,或者存在虚假唤醒的情况
synchronized (obj) {
while (!conditionMet()) {
obj.wait(); // 使用 while 循环检查条件
}
}- 虚假唤醒
- Java 规范允许 wait() 方法在没有显式调用 notify() 或 notifyAll() 的情况下返回,这被称为“虚假唤醒”。因此,始终使用 while 循环来确保条件真正满足。
synchronized (obj) {
while (!conditionMet()) {
obj.wait(); // 处理虚假唤醒
}
}- 选择 notify() 还是 notifyAll()
- notify():只唤醒一个线程,适用于只需要唤醒一个线程的场景。由于 JVM 选择哪个线程不可预测,可能会导致某些线程永远无法被唤醒。
- notifyAll():唤醒所有等待中的线程,适用于多个线程都在等待同一条件变化的场景。虽然性能稍差,但更安全,避免了某些线程永远无法被唤醒的问题。
生产者与消费者示例
import java.util.LinkedList;
import java.util.Queue;
public class ProducerConsumerExample {
private final Queue<Integer> queue = new LinkedList<>();
private final int capacity = 5;
public static void main(String[] args) {
ProducerConsumerExample example = new ProducerConsumerExample();
Thread producer = new Thread(() -> {
for (int i = 0; i < 10; i++) {
example.produce(i);
}
});
Thread consumer = new Thread(() -> {
for (int i = 0; i < 10; i++) {
example.consume();
}
});
producer.start();
consumer.start();
}
public synchronized void produce(int value) {
while (queue.size() == capacity) {
try {
System.out.println("Queue is full, producer is waiting...");
wait(); // 当队列满时,生产者等待
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
queue.offer(value);
System.out.println("Produced: " + value);
notifyAll(); // 唤醒所有等待的消费者
}
public synchronized void consume() {
while (queue.isEmpty()) {
try {
System.out.println("Queue is empty, consumer is waiting...");
wait(); // 当队列空时,消费者等待
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
int value = queue.poll();
System.out.println("Consumed: " + value);
notifyAll(); // 唤醒所有等待的生产者
}
}produce() 方法:当队列满时,生产者调用 wait() 等待;当有空间时,调用 notifyAll() 唤醒所有等待的消费者。
consume() 方法:当队列空时,消费者调用 wait() 等待;当有数据时,调用 notifyAll() 唤醒所有等待的生产者。
死锁的发生原因?怎么避免?
死锁发生在两个或多个线程互相等待对方释放资源的情况下。当线程A持有资源1并等待资源2,而线程B持有资源2并等待资源1时,就会发生死锁。
一旦出现死锁,整个程序既不会发生异常,也不会给出任何提示,只是所有线程处于阻塞状态,无法继续。
死锁产生的主要原因:
- 互斥条件:资源只能被一个线程占用,如果一个线程已经占用了资源,其他线程就无法访问该资源。
- 请求与保持条件:线程在持有资源的同时又请求其他资源,而这些资源被其他线程占用,导致线程之间相互等待。
- 不可剥夺条件:已经分配给线程的资源不能被其他线程强制性地剥夺,只能由持有资源的线程主动释放。
- 循环等待条件:存在一个资源的循环链,每个线程都在等待下一个线程所持有的资源。
当以上四个条件同时满足时,就可能产生死锁。
死锁破除的解决思路:
- 针对条件 1:互斥条件基本上无法被破坏。因为线程需要通过互斥解决安全问题。
- 针对条件 2:可以考虑一次性申请所有所需的资源,这样就不存在等待的问题。
- 针对条件 3:占用部分资源的线程在进一步申请其他资源时,如果申请不到,就主动释放掉已经占用的资源。
- 针对条件 4:可以将资源改为线性顺序。申请资源时,先申请序号较小的,这样避免循环等待问题。
举例 1
package com.clear.juc.locks;
import java.util.concurrent.TimeUnit;
public class DeadLockDemo {
public static void main(String[] args) {
StringBuilder s1 = new StringBuilder();
StringBuilder s2 = new StringBuilder();
new Thread(() -> {
synchronized (s1) {
s1.append("a");
s2.append("1");
try { TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) { e.printStackTrace();}
synchronized (s2) {
s1.append("b");
s2.append("2");
System.out.println(s1);
System.out.println(s2);
}
}
}, "t1").start();
new Thread(() -> {
synchronized (s2) {
s1.append("c");
s2.append("3");
try { TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) { e.printStackTrace();}
synchronized (s1) {
s1.append("d");
s2.append("4");
System.out.println(s1);
System.out.println(s2);
}
}
}, "t2").start();
}
}举例 2:
public class TestDeadLock {
public static void main(String[] args) {
Object g = new Object();
Object m = new Object();
Owner s = new Owner(g,m);
Customer c = new Customer(g,m);
new Thread(s).start();
new Thread(c).start();
}
}
class Owner implements Runnable{
private Object goods;
private Object money;
public Owner(Object goods, Object money) {
super();
this.goods = goods;
this.money = money;
}
@Override
public void run() {
synchronized (goods) {
System.out.println("先给钱");
synchronized (money) {
System.out.println("发货");
}
}
}
}
class Customer implements Runnable{
private Object goods;
private Object money;
public Customer(Object goods, Object money) {
super();
this.goods = goods;
this.money = money;
}
@Override
public void run() {
synchronized (money) {
System.out.println("先发货");
synchronized (goods) {
System.out.println("再给钱");
}
}
}
}排除死锁的方式有哪些?
- 通过纯命令的方式
- jps -l 查询出进行编号
- jstack 进程编号
- jconsole图形化工具
示例
package com.clear.juc.locks;
import java.util.concurrent.TimeUnit;
public class DeadLockDemo {
public static void main(String[] args) {
StringBuilder s1 = new StringBuilder();
StringBuilder s2 = new StringBuilder();
new Thread(() -> {
synchronized (s1) {
s1.append("a");
s2.append("1");
try { TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) { e.printStackTrace();}
synchronized (s2) {
s1.append("b");
s2.append("2");
System.out.println(s1);
System.out.println(s2);
}
}
}, "t1").start();
new Thread(() -> {
synchronized (s2) {
s1.append("c");
s2.append("3");
try { TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) { e.printStackTrace();}
synchronized (s1) {
s1.append("d");
s2.append("4");
System.out.println(s1);
System.out.println(s2);
}
}
}, "t2").start();
}
}运行上面代码会发现终端迟迟没有结果,使用如下命令查看死锁:
D:\video\workspace\explore\springboot\juc\src\main\java\com\clear\juc\locks>jps -l
31888 com.clear.juc.locks.DeadLockDemo
11188
25748 org.jetbrains.idea.maven.server.RemoteMavenServer36
14888 sun.tools.jps.Jps
30684 org.jetbrains.jps.cmdline.Launcher
D:\video\workspace\explore\springboot\juc\src\main\java\com\clear\juc\locks>jstack 31888
2025-03-10 18:24:31
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.131-b11 mixed mode):
# 省略1万行 ^v^
Java stack information for the threads listed above:
===================================================
"t2":
at com.clear.juc.locks.DeadLockDemo.lambda$main$1(DeadLockDemo.java:30)
- waiting to lock <0x000000076e2a1258> (a java.lang.StringBuilder)
- locked <0x000000076e2a12a0> (a java.lang.StringBuilder)
at com.clear.juc.locks.DeadLockDemo$$Lambda$2/1078694789.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
"t1":
at com.clear.juc.locks.DeadLockDemo.lambda$main$0(DeadLockDemo.java:16)
- waiting to lock <0x000000076e2a12a0> (a java.lang.StringBuilder)
- locked <0x000000076e2a1258> (a java.lang.StringBuilder)
at com.clear.juc.locks.DeadLockDemo$$Lambda$1/990368553.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
Found 1 deadlock.什么是协程?Java支持协程吗?
什么是Java中的线程同步?
什么是Java中的ABA问题?
Java内存模型(JMM)?
Java内存模型(Java Memory Model)是Java虚拟机(JVM)定义的一种规范(抽象概念,并不真实存在),用于描述多线程程序中变量(包括实例字段、静态字段和数组元素)如何在内存中存储和传递。规范了线程何时会从主内存中读取数据、何时会把数据写回主内存。
JMM能干嘛?
1、通过JMM来实现线程和主内存之间的抽象关系
2、屏蔽各个硬件平台和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果。
JMM的核心目标是确保多线程环境下的原子性、可见性和有序性,从而避免硬件和编译器优化带来的不一致问题
- 可见性:确保一个线程对变量的修改,能及时被其他线程看到。
- 关键字
volatile就是用来保证可见性的,它强制线程每次读写时都直接从主内存中获取最新值
- 关键字
- 有序性:指线程执行操作的顺序。JMM允许某些指令重排以提高性能,但会保证线程会的操作顺序不会被破坏,并通过
happens-before关系保证跨线程的有序性。 - 原子性:是指操作不可分割,线程不会在执行过程中被中断。
- 例如,
synchronized关键字能确保方法或代码块的原子性 - JMM 保证了基本数据类型的读写操作的原子性,但对于复合操作(如 i++)则不保证
- 例如,
关键概念
线程与主内存:
每个线程都有自己的工作内存(也称为本地内存),工作内存保存了该线程使用到的变量的副本。主内存是共享内存区域,所有线程都可以访问主内存中的变量
注意!!!
这里说的本地内存也是一种抽象的概念,实际上可能指的是寄存器、CPU缓存等
内存模型中的同步机制
volatile关键字
volatile变量保证了对该变量的读写操作的可见性和有序性。
读volatile变量时,总是从主内存中读取最新的值。
写volatile变量时,总是将最新的值写回主内存。
synchronized关键字
synchronized块或方法保证了进入临界区的线程对共享变量的独占访问。
退出synchronized块时,会将工作内存中的变量更新到主内存。
进入synchronized块时,会从主内存中读取最新的变量值。
final关键字
final变量在构造器中初始化后,其他线程可以立即看到初始化后的值。
final变量的引用不会被修改,因此可以确保其可见性。
可见性问题示例
public class VisibilityExample {
private static boolean stop = false;
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
while (!stop) {
// busy-wait
}
});
thread.start();
Thread.sleep(1000);
stop = true; // 另一个线程可能不会立即看到这个修改
}
}主线程修改了stop变量,但另一个线程可能不会立即看到修改,导致循环无法终止。可以使用volatile关键字解决这个问题:
public class VisibilityExample {
private static volatile boolean stop = false;
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
while (!stop) {
// busy-wait
}
});
thread.start();
Thread.sleep(1000);
stop = true; // 另一个线程会立即看到这个修改
}
}JMM规范下,三大特性?
JMM的核心目标是确保多线程环境下的原子性、可见性和有序性,从而避免硬件和编译器优化带来的不一致问题
- 可见性:确保一个线程对变量的修改,能及时被其他线程看到。
- 关键字
volatile就是用来保证可见性的,它强制线程每次读写时都直接从主内存中获取最新值
- 关键字
- 有序性:指线程执行操作的顺序。JMM允许某些指令重排以提高性能,但会保证线程会的操作顺序不会被破坏,并通过
happens-before关系保证跨线程的有序性。 - 原子性:是指操作不可分割,线程不会在执行过程中被中断。
- 例如,
synchronized关键字能确保方法或代码块的原子性 - JMM 保证了基本数据类型的读/写操作的原子性,但对于复合操作(如 i++)则不保证
- 例如,
可见性
是指当一个线程修改了某一个共享变量的值,其他线程能够立刻知道该变更
JMM规定了所有的变量都存储在主内存中
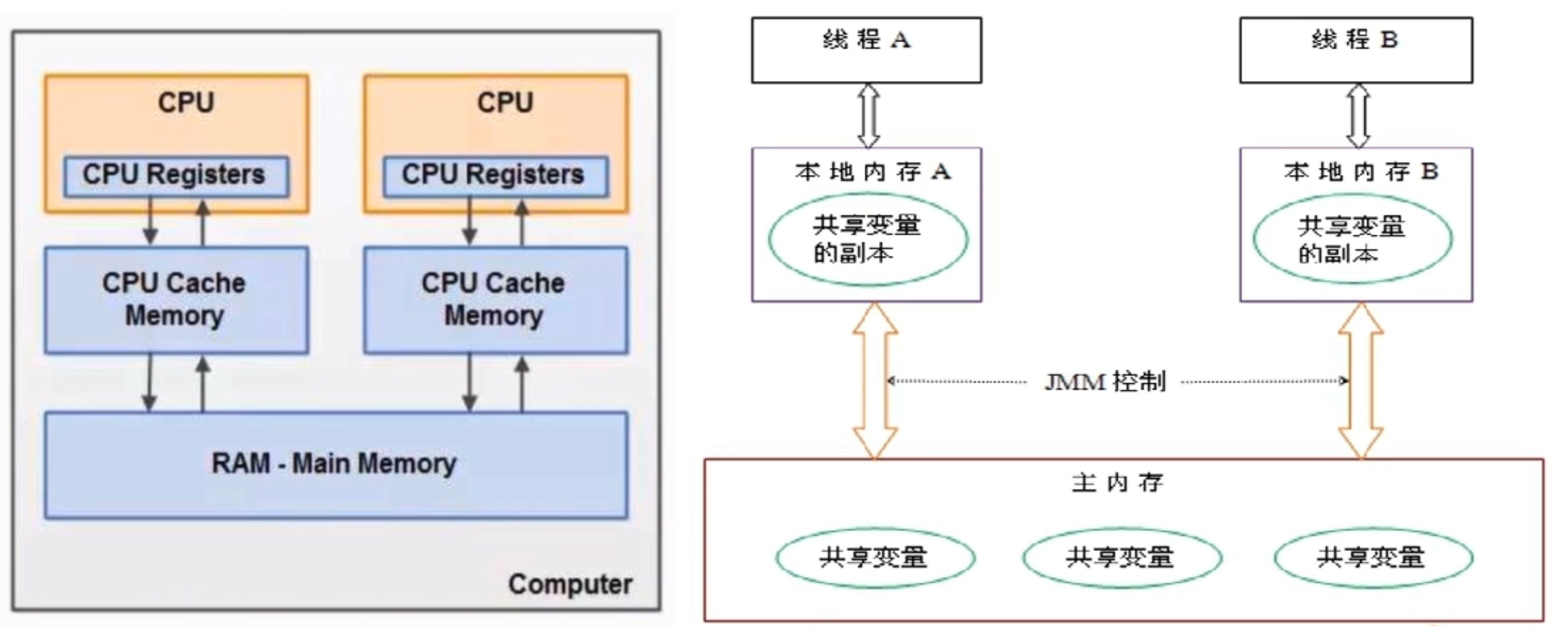
系统主内存共享变量数据修改被写入的时机是不确定的,多线程并发下很可能出现“脏读”,所有每个线程都有自己的工作内存(本地内存)。
线程自己的工作内存中保存了该线程使用到的变量的主内存副本拷贝,线程对变量的所有操作(读写、赋值等)都必须在自己的工作内存中进行,而不能够直接读写主内存中的变量。
不同线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成。
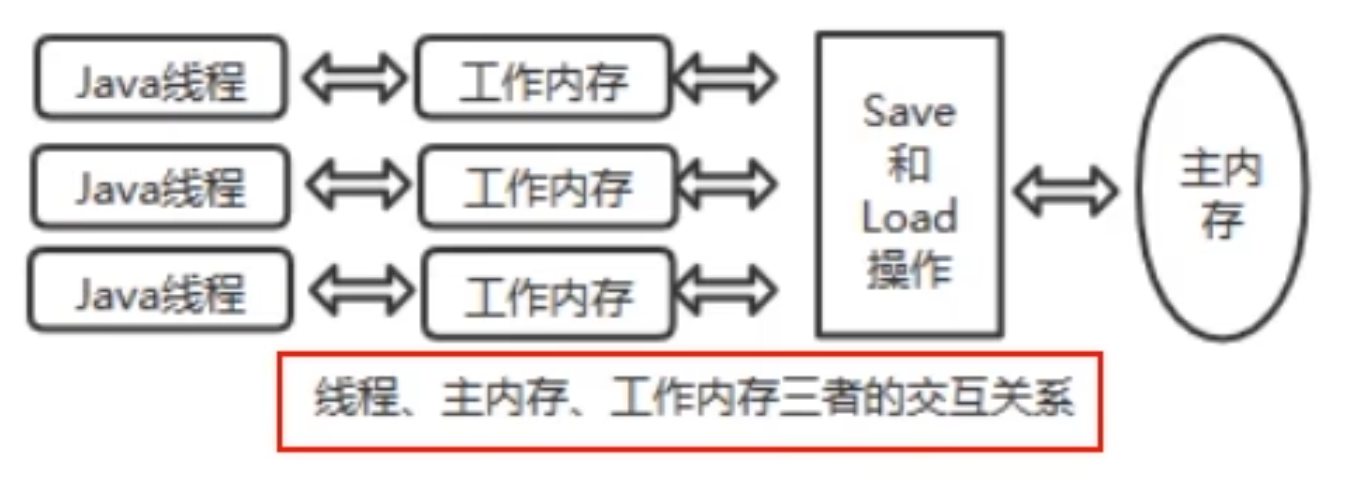
线程脏读
假设主内存中有变量x,初始值为0
线程A要将x + 1,先将 x = 0 拷贝到自己的工作内存中,然后进行更新x值
线程A将更新后的x值回刷到主内存的时间是不固定的
刚好在线程A没有回刷x到主内存时,线程B同时从主内存中读取x,此时x = 0,和线程A执行一样的操作
最后,期盼的结果 x = 2,就会变为 x = 1
因此Java引入了
volatile关键字用来保证可见性的,它强制线程每次读写时都直接从主内存中获取最新值
原子性
指操作不可分割,线程不会在执行过程中被中断。即在多线程环境下,操作不能被其他线程干扰
有序性
对于一个线程的执行代码而言,我们总是习惯性的认为代码的执行总是从上到下,有序执行的。
但为了提升性能,编译器和处理器通常会对执行序列进行重新排序。
Java规范规定JVM线程内部维持顺序语义化,即只要程序的最终结果与它顺序化执行的结果相等,那么指令的执行顺序可以与代码顺序不一致,这个过程叫指令的重排序。
优缺点:
JVM能根据处理器特性(CPU多级缓存系统、多核处理器等)适当的对机器指令进行重排序,使机器指令能更符合CPU的执行特性,最大限度的发挥机器性能。
但是,指令重排可以保证串行语义一致,但没有义务保证多线程间的语义也一致(即可能产生“脏读”等)。
简单来说,两个以上不相干的代码在执行的时候,有可能先执行的不是第一条,不见得是从上到下顺序执行,执行顺序会被优化。

单线程环境里面,确保程序最终执行结果和代码顺序执行的结果一致。
处理器在进行重排序时必须要考虑指令之间的数据依赖性。
多线程环境中线程交替执行,由于编译器优化重排的存在,两个线程中使用的变量能否保持一致性是无法确定的,结果也是无法预测的。
线程的安全三大特性
线程安全确保多个线程能够正确、无冲突地访问共享资源。线程安全的三大核心特性是原子性、可见性和有序性。
原子性 (Atomicity)
原子性指的是一个操作或一系列操作要么全部执行,要么全部不执行,中间不会被其他线程干扰。原子操作是不可分割的,任何线程都不能中断它们。
原子操作:如读取和写入单个变量。
非原子操作:如自增操作i++(它实际上包括读取、更新和写入三个步骤)。
解决方案:
使用同步块或锁(如ReentrantLock)来确保操作的原子性。
使用原子类(如AtomicInteger、AtomicLong等)来处理基本类型的原子操作
- CAS:Java的原子类底层是依赖于CAS操作实现原子性。CAS是一种硬件级指令,它比较内存位置的当前值与给定的旧值,如果相等则将内存位置更新为新值,此过程的原子性由操作系统保证。CAS避免了传统锁机制带来的上下文切换开销。
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicExample {
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet(); // 原子性自增操作
}
}可见性 (Visibility)
可见性指的是一个线程对共享变量的修改,能够及时被其他线程看到。
多线程环境下,线程对共享变量的修改可能不会立即被其他线程感知,因为每个线程都有自己的缓存(如CPU缓存)。一个线程修改了一个变量,但另一个线程读取到的仍然是旧值。
解决方案:
- 使用
volatile关键字:确保变量的修改对所有线程立即可见。它强制线程每次读写时都直接从主内存中获取最新值 - 使用同步块或锁:同步块不仅可以保证原子性,还可以保证可见性。每次进入和退出同步块的线程都能够看到块内变量的最新值。(每次线程退出同步块时,都会将修改后的变量值刷新到主内存中,进入块的线程则会从主内存中读取最新的值)
- 线程间通信机制:如wait()和notify()。
有序性 (Ordering)
有序性指的是程序执行的顺序按照代码的顺序来执行。
但在多线程环境下,由于编译器优化和CPU指令重排,代码的执行顺序可能与编写顺序不同。指令重排可能导致线程看到不一致的执行顺序。
解决方案:
- 使用volatile关键字:不仅保证可见性,还禁止指令重排。
- 使用同步块或锁:同步块不仅可以保证原子性和可见性,还可以保证进入和退出同步块的代码顺序。
- 内存屏障(Memory Barriers):低级别的控制指令重排的技术。
public class OrderingExample {
private int a = 0;
private boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if (flag) { // 3
int i = a; // 4
// 这里i可能是0,因为1和2可能被重排
}
}
}总结
原子性:确保操作不可分割,使用同步块、锁或原子类。
可见性:确保线程间的修改及时可见,使用volatile关键字、同步块或锁。
有序性:确保代码执行顺序符合预期,使用volatile关键字、同步块或内存屏障
什么是Java的happens-before规则?(JMM规范)
在JMM中,如果一个操作的执行结果需要对另一个操作可见性 或者 代码重排序,那么这两个操作之间必须存在happens-before(先行发生)原则
happens-before规则是Java内存模型(JMM)中的核心概念,用于定义多线程程序在操作的可见性和顺序性。
它通过指定一系列操作之间的关系,确保线程间的操作是有序的,避免了由于重排序或线程间数据不可见导致的并发问题。
通过happens-before关系,我们可以推断出线程之间的内存操作如何相互影响,从而确保线程安全。
Happens-before原则的定义
1、如果一个操作A happens-before另一个操作B,那么在多线程环境中,A的结果对B是可见的,并且A在时间上先于B执行。
2、如果两个操作之间存在 happens-before 关系,并不意味着一定要按照 happens-before 原则制定的顺序来执行。如果重排序之后的执行结果与按照happens-before关系来执行的结果一致,那么这种重排序并不非法。
具体来说,happens-before关系确保了两个操作之间的可见性和顺序性。
happens-before规则的主要规则
1)程序次序规则(Program Order Rule):在一个线程中,按照程序顺序(按照代码的书写顺序),前面的操作happens-before后面的操作。
2)监视器锁规则(Monitor Lock Rule):对一个锁的解锁(unlock)操作happens-before后续对同一个锁的加锁(lock)操作。也就是说,在释放锁之前的所有修改在加锁后对其他线程可见。
3)传递性(Transitivity):如果操作A happens-before操作B,且操作B happens-before操作C,那么操作A happens-before操作C。
4)volatile变量规则:对一个volatile变量的写操作 happens-before 后续对这个 volatile 变量的读操作。他保证volatile变量的可见性,确保一个线程修改volatile变量后,其他线程能立即看到最新值。
5)线程启动规则(Thread Start Rule):在一个线程中,对另一个线程的Thread.start()调用happens-before该线程中的任何操作。
6)线程终止规则(Thread Termination Rule):一个线程中的所有操作happens-before另一个线程调用该线程的Thread.join()并成功返回。
7)线程中断规则(Interrupt Rule):对线程的Thread.interrupt()调用happens-before被中断线程检测到中断事件的发生(通过Thread.isInterrupted()或抛出InterruptedException)。
8)对象构造规则(Object Construction Rule):一个对象的构造函数的结束happens-before该对象的finalize()方法的开始。
Happens-before原则的应用
程序次序规则
int a = 1; // 操作A
int b = 2; // 操作B在同一个线程中,操作A happens-before操作B,确保了操作A的结果对操作B可见。
监视器锁规则
synchronized(lock) {
// 操作A
}
synchronized(lock) {
// 操作B
}对lock的解锁操作(操作A)happens-before对同一个lock的加锁操作(操作B)
线程启动规则
Thread t = new Thread(() -> {
// 操作B
});
t.start(); // 操作A在主线程中,对Thread t的start()调用(操作A)happens-before新线程中的任何操作(操作B)
Happens-before原则的意义
Happens-before原则为开发者提供了一套明确的规则,用于推断多线程程序中操作的执行顺序和内存可见性。这有助于编写正确和高效的并发程序,避免数据竞争和其他并发问题。通过遵循这些规则,开发者可以确保线程间的正确同步,确保程序的正确性和稳定性。
volatile关键字的作用?
volatile 是 Java 中的一个关键字,用于修饰变量,以确保变量的可见性和有序性,它强制线程每次读写时都直接从主内存中获取最新值
volatile保证线程的可见性和有序性,依靠的是内存屏障
volatile的特性
- 可见性
volatile关键字确保一个线程对变量的修改会立即被其他线程可见。
也就是说,当一个线程修改了volatile变量的值,新值会立即刷新到主内存中,并且其他线程读取这个变量时会直接从主内存中读取最新的值,而不是从线程的本地缓存(工作内存)中读取。
- 有序性
有序性指的是程序执行的顺序按照代码的顺序来执行。
在多线程环境下,由于编译器优化和CPU指令重排,代码的执行顺序可能与编写顺序不同。指令重排可能导致线程看到不一致的执行顺序。
重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的手段,有时候可能会改变程序语句的先后顺序。
不存在数据依赖关系,可以重排序;否则,禁止重排序
例如:
int x = 1; int y = x + 3; // 禁止重排序,因为存在数据依赖
特别注意!!!重排序后的指令不能改变原有的串行语义!这一点在并发设计中必须重点考虑。
写屏障(Store Barrier):在写入 volatile 变量之后插入,确保在写入 volatile 变量之前的所有写操作都已经完成(所有在缓存中的数据同步到主内存中),并且这些写操作的结果对其他线程可见。
读屏障(Load Barrier):在读取 volatile 变量之前插入,确保在读取 volatile 变量之后的所有读操作都从主内存中获取最新的值。
volatile的用法
volatile关键字通常用于修饰那些在多个线程之间共享的变量,确保这些变量的修改能够及时被其他线程看到。
volatile实现了Java内存模型中的可见性和有序性(禁重排),但不保证原子性。
public class VolatileExample {
private volatile boolean flag = false;
public void writer() {
flag = true;
}
public void reader() {
if (flag) {
// 读取到最新的flag值
System.out.println("Flag is true");
}
}
public static void main(String[] args) {
VolatileExample example = new VolatileExample();
Thread writerThread = new Thread(() -> {
example.writer();
});
Thread readerThread = new Thread(() -> {
example.reader();
});
writerThread.start();
readerThread.start();
}
}在上述代码中,flag变量被声明为volatile,确保writer()方法对flag的修改能够被reader()方法及时看到
使用volatile的场景
适用场景
- 单一赋值操作
- 例如:volatile int a = 10; volatile boolean flag = false;
- 状态标志:如布尔型标志,用于控制线程的启动和停止。
- 例如:volatile static boolean flag = false;
- DCL双端锁的发布、单例模式:在双重检查锁定(Double-Checked Locking)的单例模式中,使用volatile修饰实例变量,确保实例变量的可见性和有序性。
- 开销较低的读写锁策略,例如:
/**
* 适用于 读远多于写,使用volatile减少同步的开销
*/
public class VolatileCounter {
// 使用 volatile 修饰变量 i,确保每个线程读取的值是最新的
private volatile int i = 0;
// 读取 i 的方法,利用volatile保证读操作的可见性
public int read() {
return i;
}
// 写入 i 的方法,使用 synchronized 确保写操作的原子性
public synchronized void increment() {
i++;
}
}不适用场景
复合操作:如自增操作(i++)、累加操作等。这些操作不是原子的,使用volatile不能保证线程安全。此时应使用同步块或原子类。
依赖于前后操作顺序的场景:如需要严格的操作顺序控制,应使用同步块或锁
volatile的局限性
volatile只能保证对单个volatile变量的读/写操作是可见的和有序的,但不能保证复合操作(如i++)的原子性。
volatile不能替代锁,不能保证多个操作的原子性和完整性。如果需要更复杂的同步机制,仍需使用同步块或锁。
什么是Java中的指令重排?
重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种技术,旨在提高程序执行效率。它允许编译器和处理器在不改变程序最终结果的前提下,重新排列指令的执行顺序。指令重排可以利用处理器的并行执行能力和优化内存访问,以提高程序的性能。
重排序的几个考虑因素
- 存在数据依赖关系,禁止重排序
- 重排序后指令绝不不能改变原有串行语义!!!
为什么需要指令重排?
提高指令级并行性:现代处理器具有多条流水线,可以同时执行多条指令。通过重排指令,可以更好地利用这些流水线,提高指令级并行性。
减少等待时间:某些指令可能会因为数据依赖或内存访问延迟而等待。通过重排指令,可以将这些等待时间隐藏在其他指令的执行过程中,从而提高整体执行效率。
指令重排的类型

- 编译器重排:编译器在生成目标代码时,在不改变单线程串行语义的前提下,可以重新调整指令的执行顺序。这种重排通常基于数据流分析和依赖关系分析。
- 处理器重排:现代处理器使用指令级并行技术将多条指令重叠执行,若不存在数据依赖,处理器可以改变语句对应机制指令的执行顺序,以提高执行效率。这种重排利用了处理器的乱序执行(Out-of-Order Execution)能力。
- 内存系统重排:由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是乱序执行的。
指令重排 Demo
假设有以下两条指令:
int a = 1; // 指令1
int b = 2; // 指令2在没有数据依赖的情况下,编译器或处理器可以将这两条指令的顺序互换,而不会影响程序的最终结果:
int b = 2; // 指令2
int a = 1; // 指令1指令重排:
在单线程环境里面,可以确保程序最终执行结果和代码顺序执行的结果一致。因为处理器在进行重排序时必须要考虑指令之间的数据依赖性。
而上面的代码很明显不存在依赖。
指令重排对多线程编程的影响
在多线程环境中,指令重排可能会导致意想不到的结果,尤其是在没有适当的同步机制时。考虑以下示例:
// 线程1
x = 1; // 指令1
y = 2; // 指令2
// 线程2
if (y == 2) {
// 期望x == 1
}在单线程环境中,我们可以合理地认为,如果y的值是2,那么x的值应该是1。然而,由于指令重排,可能会出现以下情况:
// 线程1
y = 2; // 指令2
x = 1; // 指令1
// 线程2
if (y == 2) {
// 可能x != 1
}在这种情况下,线程2可能会在y被设置为2之后,但在x被设置为1之前执行,从而导致不一致的状态。
如何防止指令重排
为了防止指令重排导致的多线程问题,可以使用以下方法:
volatile关键字:在Java中,使用volatile关键字可以禁止特定类型的指令重排。声明为volatile的变量在被写入时会立即被刷新到主内存,在被读取时会从主内存中读取,确保变量的可见性和有序性。
同步机制:使用同步块(synchronized)或显式锁(如ReentrantLock)可以确保在同步块内的指令按预期顺序执行,防止指令重排。
内存屏障:在底层,内存屏障(Memory Barrier)或内存栅栏(Memory Fence)是一种指令,用于防止特定类型的指令重排。如Java的 Unsafe 类提供了对内存屏障的支持
为什么指令重排能够提高性能?
指令重排是指编译器或处理器在不改变程序语义的前提下,重新安排指令的执行顺序,以提高程序执行效率的一种优化技术
用处理器的乱序执行能力
现代处理器通常具有乱序执行能力,这意味着处理器可以根据指令的依赖关系和资源可用性,动态地调整指令的执行顺序。这样做的主要目的是最大化处理器资源的利用率,减少等待时间。
假设有以下指令序列:
int a = loadFromMemory(address1); // 指令1
int b = a + 5; // 指令2
int c = loadFromMemory(address2); // 指令3
int d = c * 2; // 指令4指令1和指令2存在数据依赖关系,而指令3和指令4则与前两条指令无关。处理器可以重排指令,使得指令3在指令1之后立即执行,而不必等待指令2的执行结果:
int a = loadFromMemory(address1); // 指令1
int c = loadFromMemory(address2); // 指令3
int b = a + 5; // 指令2
int d = c * 2; // 指令4这样,处理器可以在等待指令1的内存读取时,先执行指令3,从而减少整体等待时间,提高执行效率。
减少数据依赖导致的等待时间
指令重排可以减少由于数据依赖(Data Dependency)导致的等待时间。数据依赖指的是一条指令需要等待前一条指令的结果才能执行。
假设有以下指令序列:
int a = loadFromMemory(address1); // 指令1
int b = a + 5; // 指令2
int c = loadFromMemory(address2); // 指令3
int d = c * 2; // 指令4指令2依赖于指令1的结果,但指令3和指令4与前两条指令无关。处理器可以重排指令,使得指令3和指令4在指令2之前执行,从而减少等待时间:
int a = loadFromMemory(address1); // 指令1
int c = loadFromMemory(address2); // 指令3
int d = c * 2; // 指令4
int b = a + 5; // 指令2这样,指令3和指令4可以在等待指令1的内存读取时执行,从而减少整体等待时间,提高执行效率。
提高指令级并行性
指令重排可以提高指令级并行性(Instruction-Level Parallelism, ILP),即在同一时刻可以并行执行的指令数量。通过重排指令,可以更好地填充处理器的流水线(Pipeline),减少流水线停顿(Pipeline Stalls)。
假设处理器有两个执行单元,可以同时执行两条指令。原始指令序列:
int a = loadFromMemory(address1); // 指令1
int b = a + 5; // 指令2
int c = loadFromMemory(address2); // 指令3
int d = c * 2; // 指令4如果处理器重排指令,将指令3提前:
int a = loadFromMemory(address1); // 指令1
int c = loadFromMemory(address2); // 指令3
int b = a + 5; // 指令2
int d = c * 2; // 指令4这样,指令1和指令3可以同时执行,提高了指令级并行性。
隐藏内存访问延迟
内存访问通常比处理器执行指令要慢得多。指令重排可以将内存访问的延迟隐藏在其他指令的执行过程中,从而提高整体性能。
假设有以下指令序列:
int a = loadFromMemory(address1); // 指令1
int b = a + 5; // 指令2
int c = loadFromMemory(address2); // 指令3
int d = c * 2; // 指令4处理器可以重排指令,将两个加载指令分开,以隐藏内存访问延迟:
int a = loadFromMemory(address1); // 指令1
int c = loadFromMemory(address2); // 指令3
int b = a + 5; // 指令2
int d = c * 2; // 指令4这样,在等待加载数据的同时,处理器可以执行其他指令,提高了整体效率
volatile如何防止指令重排?
在Java中,volatile关键字用于修饰变量,以确保对该变量的读写操作具有可见性和有序性。具体来说,volatile变量的读写操作会有以下两个主要特性:
可见性:当一个线程修改了volatile变量的值,新的值对于其他所有线程立即可见。
有序性:volatile关键字可以防止指令重排,从而保证代码执行的顺序性。
volatile关键字防止指令重排的机制主要依赖于内存屏障(Memory Barriers,也称为内存栅栏)。
内存屏障是一种指令,用于限制处理器和编译器对指令的重排序行为。
内存屏障主要有以下几种类型,每种类型的屏障对内存操作的重排序有不同的限制:
LoadLoad Barrier
- 确保在此屏障之前的所有读操作在屏障之后的读操作之前完成。
- 示例:Load1; LoadLoad; Load2 保证Load1在Load2之前完成。
StoreStore Barrier
- 确保在此屏障之前的所有写操作在屏障之后的写操作之前完成。
- 示例:Store1; StoreStore; Store2 保证Store1在Store2之前完成。
LoadStore Barrier
- 确保在此屏障之前的所有读操作在屏障之后的写操作之前完成。
- 示例:Load1; LoadStore; Store2 保证Load1在Store2之前完成。
StoreLoad Barrier
- 确保在此屏障之前的所有写操作在屏障之后的读操作之前完成。StoreLoad屏障通常是最昂贵的,因为它会导致处理器流水线的刷新。
- 示例:Store1; StoreLoad; Load2 保证Store1在Load2之前完成。
在Java中,volatile变量的读写操作会插入特定的内存屏障,以确保有序性:
读屏障
在每个volatile读操作的后面插入一个loadload屏障,禁止处理器把上面的volatile读与下面的普通读重排序。
在每个volatile读操作的后面插入一个loadstore屏障,禁止处理器把上面的volatile读与下面的普通写重排序。
写屏障
在每个volatile写操作的前面插入一个storestore屏障,可以保证在volatile写之前,其前面的所有普通写操作都已经刷新到主内存中。
在每个volatile写操作的后面插入一个storeload屏障,作用是避免volatile写与后面可能有的volatile读/写操作重排)
volatile保证线程的可见性和有序性,不保证原子性是为什么?
保证线程的可见性
可见性原理
在多线程环境中,每个线程都有自己的工作内存(缓存),从主存中读取变量复制到工作内存中进行操作,操作完成后再写回主存。
普通变量的修改在一个线程中进行后,其他线程并不一定能立即看到,因为这个修改可能只存在于工作内存中,尚未刷新到主存。(变量副本写回主存的时机是不确定的)
volatile关键字通过一套内存屏障(Memory Barrier)机制来保证变量的可见性。具体来说,当一个变量被声明为volatile时:
写操作:在写入volatile变量时,会在写操作之后插入一个写屏障(Store Barrier)。这确保了在写入volatile变量之前,对共享变量的修改会被同步到主存中。
读操作:在读取volatile变量时,会在读操作之前插入一个读屏障(Load Barrier)。这确保了在读取volatile变量之后,能从主存中获取最新的值。
简单点来说,volatile关键字之所以能够保证可见性,是因为它强制线程每次读写时都直接从主内存中获取最新值
public class VolatileVisibilityDemo {
// static boolean flag = false;
volatile static boolean flag = false;
public static void main(String[] args) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\tcome in");
while (!flag) {
// Busy-wait
}
}, "t1").start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
flag = true;
System.out.println(Thread.currentThread().getName() + "修改flag:" + flag);
}
}在这个例子中,主线程将flag被设置为true,并且这个修改会立即被刷新到主存中。而t1线程会从主存中读取flag的最新值,从而跳出循环。
如果flag变量不加volatile修饰,t1线程有可能会看不到main线程对flag的修改,为什么?
可能原因:
1)main线程修改了flag的值,但是没有将其刷新到主内存中,所以t1线程看不到
2)main线程将flag最新值刷新到了主内存中,但t1线程一直在读取自己工作内存的flag值,没有去主内存中获取最新值(典型的自娱自乐)
解决方案:使用volatile修饰flag变量,强制线程每次读写flag变量时都从主内存中获取
保证有序性
有序性原理
在 Java 内存模型中,编译器和处理器为了优化性能,可能会对指令进行重排序。重排序不会影响单线程程序的正确性,但在多线程环境下可能会导致不可预期的问题。
volatile关键字通过内存屏障来防止指令重排,从而保证有序性。
写操作:在写入volatile变量时,会在写操作之前插入一个写屏障。这确保了在写入volatile变量之前的所有写操作都不会被重排序到写屏障之后。
读操作:在读取volatile变量时,会在读操作之后插入一个读屏障。这确保了在读取volatile变量之后的所有读操作都不会被重排序到读屏障之前。
public class VolatileOrderingExample {
private volatile int a = 0;
private int b = 0;
public void writer() {
a = 1; // Write to volatile variable
b = 2; // Write to non-volatile variable
}
public void reader() {
if (a == 1) {
// If this condition is true, it guarantees that b == 2 due to the happens-before relationship
System.out.println("b = " + b);
}
}
}由于a是volatile变量,写入a之前的所有写操作(包括写入b)在写入a之后对其他线程都是可见的。因此,如果a == 1,那么b必然已经被写入2。
为什么不保证原子性
原子性原理
原子性指的是一个操作是不可分割的,即操作要么全部执行完毕,要么完全不执行。
volatile保证了对变量的单次读/写操作是原子的,但无法保证复合操作(如自增、自减)的原子性。
class MyNumber {
// int count;
volatile int count;
public void add() {
count++;
}
}
public class VolatileNotAtomicityDemo {
public static void main(String[] args) {
MyNumber number = new MyNumber();
CountDownLatch downLatch = new CountDownLatch(10);
for (int i = 0; i < 10; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
number.add();
}
downLatch.countDown();
}).start();
}
try {
downLatch.await(2, TimeUnit.SECONDS);
System.out.println(number.count);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}在这个例子中,count++实际上包含了三个步骤:
1、读取count的值
2、将count的值加 1
3、将新值写回count
这些步骤并不是一个原子操作,可能会被其他线程打断。例如,两个线程同时执行add()方法时,可能会发生竞态条件,导致count的值不如预期。例如:
- 线程 A 读取count的值为 0
- 线程 B 读取count的值为 0
- 线程 A 将count的值加 1 并写回(count变为 1)
- 线程 B 将count的值加 1 并写回(count变为 1)
最终count的值是 1 而不是 2
扩展
既然volatile不能保证(复合操作的)原子性?那怎么才能保证原子性呢?
使用同步块或锁(如ReentrantLock)来确保操作的原子性。
使用原子类(如AtomicInteger、AtomicLong等)来处理基本类型的原子操作
什么是内存屏障?
内存屏障(也称为内存栅栏、屏障指令等,是一类同步屏障指令),是一种用于控制处理器和编译器对内存操作进行重排序的指令(避免重排序)。
内存屏障确保在特定点之前的内存操作完成后,才会进行该点之后的内存操作。因为它们可以确保内存操作的可见性和有序性,从而避免数据竞争和其他并发问题。
内存屏障其实是一种JVM指令,Java内存模型的重排序规则会要求Java编译器在生成JVM指令时插入特定的内存屏障指令,通过这些内存屏障指令,volatile实现了Java内存模型中的可见性和有序性(禁重排),但不保证原子性。
内存屏障的类型
内存屏障大致可以分为两类:
写屏障(Store Barrier):在写指令之后插入写屏障,强制把写缓冲区的数据刷回主内存中
读屏障(Load Barrier):在读指令之前插入读屏障,让工作内存或CPU高速缓存当中的缓存失效,重新回到主内存中获取最新数据
细致一点分可以分为四类:
LoadLoad Barrier
- 确保在此屏障之前的所有读操作在屏障之后的读操作之前完成。
- 示例:Load1; LoadLoad; Load2 保证Load1在Load2之前完成。
StoreStore Barrier
- 确保在此屏障之前的所有写操作在屏障之后的写操作之前完成。
- 示例:Store1; StoreStore; Store2 保证Store1在Store2之前完成。
LoadStore Barrier
- 确保在此屏障之前的所有读操作在屏障之后的写操作之前完成。
- 示例:Load1; LoadStore; Store2 保证Load1在Store2之前完成。
StoreLoad Barrier
- 确保在此屏障之前的所有写操作在屏障之后的读操作之前完成。StoreLoad屏障通常是最昂贵的,因为它会导致处理器流水线的刷新。
- 示例:Store1; StoreLoad; Load2 保证Store1在Load2之前完成。
内存屏障的作用
内存屏障在多线程编程中有以下几个主要作用:
- 禁止指令重排
编译器和处理器可能会对指令进行重排,以优化性能。
然而,在多线程环境下,这种重排可能会导致数据不一致。
对于编译器的重排序,JMM会根据重排序的规则,禁止特定类型的编译器重排序。
对于处理器的重排序,Java编译器在生成指令序列的适当位置,插入内存屏障指令,来禁止特定类型的处理器重排序。
- 确保内存可见性
内存屏障确保一个线程对内存的修改对其他线程立即可见。这对于实现正确的同步原语(如锁、信号量)至关重要。
内存屏障在Java中的实现
在Java中,volatile关键字通过内存屏障来实现其可见性和有序性保证。具体来说,volatile变量的读写操作会插入相应的内存屏障。
假设有以下代码:
volatile boolean flag = false;
int a = 0;
// Thread 1
a = 1; // 普通写操作
flag = true; // volatile 写操作
// Thread 2
if (flag) { // volatile 读操作
System.out.println(a); // 普通读操作
}在这段代码中:
Thread 1:
a = 1是普通写操作。
flag = true是volatile写操作。在这之后插入了StoreStore Barrier和StoreLoad Barrier。
这确保了a = 1在flag = true之前完成,并且flag = true之后的任何读操作不会被重排到flag = true之前。
Thread 2:
if (flag)是volatile读操作。在这之前插入了LoadLoad Barrier和LoadStore Barrier。
这确保了if (flag)之前的任何读操作不会被重排到if (flag)之后,并且if (flag)之后的任何写操作不会被重排到if (flag)之前。
final关键字能否保证变量的可见性?
不可以。
你可能看到有些观点说final能够保证可见性,那不是我们常说的可见性,下面探讨一下我们所说的可见性。
一般而言,我们指的可见性是一个线程修改了共享变量,其他线程能够立马感知到修改,得到最新修改的值。
这样子一说,我们很容易的可以联想到 volatile 关键字可以保证这种可见性。
而 final 并不能保证其他线程能够立刻感知到变量的修改,他只能够保证final修饰的变量在构造器正确执行之后初始值对其他线程的可见性。
有些观点说 final 能够保证可见性,指的是 final 修饰的字段在构造器初始化完成,并且期间没有把 this 传递出去(即 没有this逸出),那么当构造器执行完毕之后,其他线程就能够看到 final 字段的初始值。
如果不用 final 修饰的话,那么有可能在构造器中对字段的写操作会被重排序到外面,这样别的线程就拿不到写操作之后的值了(可能会获取到未完全初始化的值)。
final关键字的可见性保证
对象正确构造时的可见性
当一个对象被正确构造(无
this引用逸出)且其final字段在构造器中完成初始化后,其他线程访问该对象时,能确保看到final字段的初始值。这是由Java内存模型(JMM)的特殊规则保证的:
- 禁止重排序:JVM会确保
final字段的初始化操作不会被重排序到构造器之外,从而避免其他线程看到未完全初始化的值。- 安全发布:只要对象引用未在构造过程中逸出,
final字段的值在对象发布到其他线程时一定是构造器完成后的值。
对于 final 域,编译器和处理器要遵守两个重排序规则
1、在构造器内对一个final 域写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。(这样可以保证 final 域在对象被其他线程可见前,已经被正确初始化了)
2、当一个线程首次读取某个对象的引用时,不能与随后读取该对象的 final 域的操作重排序。(这确保了当一个线程看到对象引用时,也能正确读取 final 域的值,而不会拿到过期数据)
所以,这才是 fianl 的可见性,此可见性并非并发编程中谈到的可见性。
| 机制 | 保证可见性范围 | 适用场景 |
|---|---|---|
| final | 仅限构造器初始化的值, 对于可变类型,例如集合,final仅保证了引用本身的可见性,其内部状态的修改仍需要进行同步以确保并发下的可见性。 | 不可变字段的线程安全发布 |
| volatile | 变量修改的即时可见性 | 多线程共享变量的实时同步 |
| synchronized | 代码块内的可见性及原子性 | 复杂操作的互斥与状态一致性 |
final 总结
避免this逸出:确保对象构造完成后再发布引用。
优先使用final:对于不可变字段,用
final简化线程安全设计。不可变对象:若字段引用的对象本身不可变(如
String或Integer),final可彻底保证线程安全。正确构造时:
final字段的初始值对其他线程可见,无需额外同步。失效条件:构造过程中
this逸出或字段引用可变对象内部状态。适用性:适合不可变数据的线程安全发布,但需注意引用对象的可变性。
Java中为什么需要使用ThreadLocal?ThreadLocal原理
引言:
在多线程情况下,操作同一资源为了避免数据错误,会搞一个 synchronized 或者是 lock,那么如果我既不想加锁,又想保证数据安全,要怎么办呢?
这种既要又要的场景——可以使用TreadLocal
ThreadLocal源码翻译:
TreadLocal提供线程局部变量。这些变量与正常的变量不同,因为每个线程在访问ThreadLocal实例时(通过get、set方法)都有自己的、独立初始化的变量副本。ThreadLocal 实例通常是类中私有静态字段,使用它的目的是希望将状态(例如,用户id或事务id)与线程关联起来。
!!!ThreadLocal,不应该理解为本地线程,而应该理解为【线程本地变量】
ThreadLocal的实现依赖于每个线程内部维护的一个ThreadLocalMap对象。
每个线程都有自己的ThreadLocalMap,而ThreadLocalMap中存储了所有ThreadLocal变量及其对应的值。
换句话说,就是每个线程都有一个自己专属的本地变量副本,不与其他线程共享。
主要作用:解决了让每个线程绑定自己的值,通过使用get、set方法,获取默认值或将其值更改为当前线程所存的副本的值从而避免了线程安全问题。
主要组成部分
ThreadLocal 类:提供了set()、get()、remove()等方法,用于操作线程局部变量。
ThreadLocalMap 类:是ThreadLocal的内部静态类,用于存储ThreadLocal变量及其值。
Thread 类:每个线程内部都有一个ThreadLocalMap实例。
工作机制
创建ThreadLocal变量:当创建一个ThreadLocal变量时,实际上并没有分配存储空间。
获取值 (get()方法):当调用get()方法时,当前线程会通过自己的ThreadLocalMap获取ThreadLocal变量的值。
- 如果不存在,则调用initialValue()方法获取初始值。
设置值 (set()方法):当调用set()方法时,当前线程会通过自己的ThreadLocalMap设置ThreadLocal变量的值。
删除值 (remove()方法):当调用remove()方法时,当前线程会通过自己的ThreadLocalMap删除ThreadLocal变量的值。
初始化值:initialValue、withInitial(静态方法)。推荐使用withInitial进行初始化,因为支持lambda表达式,优雅
使用场景
- 数据库连接:在多线程环境中,每个线程可以使用自己的数据库连接,避免连接共享带来的问题。
- 用户会话(上下文传递):在 Web 应用中,每个线程可以维护自己的用户会话信息。
- 事务管理:在分布式系统中,每个线程可以维护自己的事务上下文,确保事务的一致性。
- 线程安全的工具类:例如SimpleDateFormat,它不是线程安全的,可以使用ThreadLocal让每个线程都有自己的实例。
ThreadLocal有哪些使用场景?
ThreadLocal是可以基于副本的隔离机制来保证共享变量修改的安全性,他的使用场景有很多
线程的上下文传递:在跨线程调用的场景中,可以使用ThreadLocal在不修改方法签名的情况下传递线程上下文新
- 比如在框架和中间件里面,把请求的相关信息(用户信息、请求id等)存储在ThreadLocal中,在后续的请求处理链路中,都可以方便的去访问这些信息
数据库的连接管理:在使用线程池的情况下,可以将数据库的连接存储在ThreadLocal中,这样每个线程可以独立管理自己的数据库连接,避免了线程之间的竞争和冲突。
- 比如Mybatis中的SqlSession对象就使用了ThreadLocal来存储当前线程的数据库会话信息
事务管理:在一些需要手动管理事务的场景中,可以使用ThreadLocal来存储事务的上下文,每个线程可以独立的控制自己的事务,保证事务的隔离性。
- 比如Spring中的TransactionSynchronizationManager类就使用了ThreadLocal来存储当前线程的事务相关的上下文信息
不过在使用ThreadLocal需要注意使用规范,避免内存泄露的问题
ThreadLocal的内存泄漏问题?
ThreadLocal的内存泄漏问题主要源于ThreadLocalMap中使用的弱引用(WeakReference)机制和线程生命周期管理不当。
内存泄漏的根本原因:ThreadLocalMap 中的值是强引用,如果线程未结束且未调用 remove(),这些值将无法被垃圾回收。
解决方法:及时调用 remove() 方法清理 ThreadLocal 的值,特别是在线程池等场景下要特别注意
ThreadLocal 的内部实现
- 每个线程都有一个
ThreadLocalMap,用于存储该线程的ThreadLocal变量。 ThreadLocalMap的键是ThreadLocal对象的弱引用(WeakReference),而值是线程本地变量的强引用。
内存泄漏原因
1)弱引用的局限性
ThreadLocalMap使用Entry类来存储键值对,其中键是ThreadLocal对象的弱引用(WeakReference<ThreadLocal<?>>),值是实际存储的数据。
当
ThreadLocal对象被回收时,ThreadLocalMap中的键会变成null,但值仍然存在(因为值是强引用)。如果线程没有结束,
ThreadLocalMap中的值无法被垃圾回收,从而导致内存泄漏。
2)线程生命周期:
在一些长生命周期的线程(如线程池中的线程)中,如果不显式地清除ThreadLocal变量,ThreadLocalMap中的值对象会一直存在,导致内存泄漏。
3)线程池的特殊场景
- 在使用线程池(如
ExecutorService)时,线程会被复用而不是销毁。 - 如果某个线程中创建了一个
ThreadLocal,但没有显式调用remove()方法清除其值,那么即使ThreadLocal对象本身被回收,ThreadLocalMap中的值仍然会占用内存,直到线程结束或手动清理。
阿里规约

如何避免ThreadLocal的内存泄漏?
为了避免 ThreadLocal 引发的内存泄漏,可以采取以下措施:
(1) 及时调用 remove() 方法
- 在使用完
ThreadLocal后,应显式调用remove()方法清除线程本地变量。
(2) 在 finally 块中清理
- 将
remove()放在finally块中,确保无论是否发生异常都能正确清理。
(3) 避免在长生命周期的线程(如:线程池)中滥用 ThreadLocal
- 线程池中的线程是长期存活的,因此更需要注意
ThreadLocal的清理。 - 如果必须使用
ThreadLocal,建议在任务执行完毕后立即清理。
(4) 自定义 ThreadLocalMap 清理逻辑
- 如果需要更复杂的清理逻辑,可以继承
ThreadLocal并重写其方法,例如initialValue()或childValue()。
示例:
public class ThreadLocalDemo {
public static void main(String[] args) {
MyData myData = new MyData();
// 模拟一个银行有3个办理业务的窗口
ExecutorService threadPool = Executors.newFixedThreadPool(3);
try {
// 模拟10个顾客来办理业务,正常情况应该 0 -> 1
for (int i = 0; i < 10; i++) {
int finalI = i;
threadPool.execute(new Thread(() -> {
try {
Integer beforeInt = myData.threadLocalField.get();
myData.add();
Integer afterInt = myData.threadLocalField.get();
System.out.println(Thread.currentThread().getName()
+ "\t工作窗口\t受理第" +
finalI + "个顾客业务处理" +
"beforeInt:" + beforeInt +
"\tafterInt:" + afterInt);
} finally {
myData.threadLocalField.remove(); // 显式清理threadlocal变量,避免内存泄露
}
}));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPool.shutdown();
}
}
}
class MyData {
ThreadLocal<Integer> threadLocalField = ThreadLocal.withInitial(() -> 0);
public void add() {
threadLocalField.set(threadLocalField.get() + 1);
}
}使用ThreadLocal是需要用弱引用来防止内存泄露?
ThreadLocal是如何实现线程资源隔离的?
ThreadLocal慎用的场景
ThreadLocal最佳实践?
Java中父子线程的共享(传递)?
注意:
ThreadLocal并不直接支持父子线程之间的数据共享,因为每个线程都有独立的副本。如果需要共享数据,可以结合其他机制(如共享变量或阻塞队列)。
这里有两个工具类可以实现父子线程数据传递:
InheritableThreadLocal(JDK自带)TransmittableThreadLocal(alibaba)
ThreadLocal:每个线程拥有独立的变量副本,线程之间无法直接共享数据。
InheritableThreadLocal:除了为每个线程提供独立的变量副本外,还允许子线程继承父线程的变量值。
注意:
子线程只能继承父线程的初始值,后续父线程对变量的修改不会影响子线程的值。
这也是Alibaba为什么要自己搞一个
TransmittableThreadLocal的原因,他解决了线程池复用的问题
TransmittableThreadLocal:它扩展了 Java 原生的 InheritableThreadLocal,支持在线程池中跨线程传递数据,有效避免了线程池复用导致的数据泄露问题
| 特性 | ThreadLocal | InheritableThreadLocal | TransmittableThreadLocal |
|---|---|---|---|
| 定义 | 每个线程拥有独立的变量副本 | 子线程可以继承父线程的变量值 | 支持在线程池和异步调用中传递上下文 |
| 是否支持父子线程共享 | 否 | 是(子线程继承父线程的值) | 是(子线程继承父线程的值) |
| 是否支持线程池场景 | 否,存在内存泄露 | 否,存在内存泄露 | 是 |
| 是否支持异步调用 | 否 | 否 | 是 |
什么是Java中的InheritableThreadLocal?
InheritableThreadLocal的核心目标是实现父子线程数据传递。父传子
ThreadLocal:每个线程拥有独立的变量副本,线程之间无法直接共享数据。
InheritableThreadLocal:除了为每个线程提供独立的变量副本外,还允许子线程继承父线程的变量值。
注意:
子线程只能继承父线程的初始值,后续父线程对变量的修改不会影响子线程的值。
这也是Alibaba为什么要自己搞一个
TransmittableThreadLocal的原因,他解决了线程池复用的问题
工作原理
当一个线程创建子线程时,InheritableThreadLocal 会将父线程的变量值复制一份给子线程。具体流程如下:
- 父线程设置
InheritableThreadLocal的值。 - 父线程创建子线程时,子线程会从父线程中复制
InheritableThreadLocal的值。 - 子线程可以访问该值,并且对该值的修改不会影响父线程或其他子线程。
使用场景
- 父子线程间的数据传递:例如,传递用户身份信息、事务上下文等。
- 日志跟踪:在分布式系统中,通过
InheritableThreadLocal传递请求 ID 或 Trace ID。
注意事项
- 性能开销:
InheritableThreadLocal的实现比普通ThreadLocal更复杂,可能会带来一定的性能开销。 - 内存泄漏风险:如果线程池复用线程,可能导致旧的
InheritableThreadLocal数据未被清理,从而引发内存泄漏。因此,在使用线程池时需特别小心。 - 线程安全:虽然
InheritableThreadLocal提供了父子线程间的值传递,但仍然需要确保数据的安全性和一致性。
什么是Java中的TransmittableThreadLocal?
TransmittableThreadLocal 是阿里巴巴开源的 TTL(Transmittable ThreadLocal) 库中的核心类,用于解决线程池场景下 ThreadLocal 数据无法传递的问题。
它扩展了 Java 原生的 InheritableThreadLocal,支持在线程池中跨线程传递数据
工作原理
TransmittableThreadLocal 的核心原理是通过拦截线程切换的过程,将父线程的 ThreadLocal 值复制到子线程中。具体实现包括以下几个方面:
- 包装线程池:通过
TtlRunnable和TtlCallable包装线程池的任务,确保任务执行时能够携带父线程的上下文。 - 异步调用支持:通过
TtlExecutors工具类,将普通的线程池转换为支持上下文传递的线程池。 - 清理机制:在任务执行完成后,自动清理线程中的上下文数据,避免内存泄漏。
特点
- 支持线程池场景:即使在线程池中复用线程,也能正确传递
ThreadLocal的值。 - 支持异步调用:在异步任务切换线程时,自动复制父线程的
ThreadLocal值到子线程。 - 兼容原生 ThreadLocal:可以无缝替代原生的
ThreadLocal和InheritableThreadLocal。
使用场景
- 分布式系统中的上下文传递:例如,传递 Trace ID、用户身份信息等。
- 线程池中的任务上下文:确保线程池中的任务能够访问正确的上下文数据。
- 异步框架中的上下文传递:在异步调用链中保持上下文一致性。
注意事项
- 内存泄漏风险:虽然 TTL 提供了自动清理机制,但仍需确保任务执行完成后及时释放资源。
- 性能影响:由于需要在线程切换时复制上下文数据,可能会带来一定的性能开销。
- 线程安全:
TransmittableThreadLocal的值在多个线程间传递时,需确保其内容是线程安全的。
为什么Netty不适用ThreadLocal而是自定义FastThreadLocal?
Java中线程安全是什么意思?
你是怎么理解线程安全问题的?
Java中线程之间是如何通信的?
如何在Java中控制多个线程的执行顺序?
线程的生命周期在Java中是如何定义的?
谈谈你对AQS的理解?AbstractQueuedSynchronizedr
口语化
简单来说,AQS是线程同步器,它是juc包中多个组件的底层实现,比如ReentrantLock、CountDownLatch、Semaphore等,底层都使用了AQS。
AQS它起到了一个抽象、封装的作用,把一些排队、入队、加锁、中断等方法提供出来,便于其他相关JUC锁的使用,具体的加锁时机、入队时机等都需要实现类自己来控制。
它主要通过维护一个共享状态(state)和一个先进先出(FIFO)的等待队列,来管理线程对共享资源的访问。
state使用 volatile 修饰,表示当前资源的状态。例如,在独占锁中,state 为 0 表示锁未被占用,为 1 表示已被占用。
当线程尝试获取资源失败时,会被加入到AQS的等待队列中。这个队列是一个变体的CLH队列,采用双向链表结构,节点包含线程的引用、等待状态以及前驱和后继节点的指针,
从本质上来说,AQS提供了两种锁的机制,分别是排它锁和共享锁。
排它锁也称为独占锁,就是当存在多个线程竞争时,同一共享资源同一时刻只允许一个线程访问。比如说Lock中的ReentrantLock的重入锁实现就使用了AQS的排它锁功能。
共享锁也称为读锁,同一时刻允许多个线程同时获得锁资源。比如说CountDownLatch、Semaphore都用到了AQS的共享锁功能。
AQS的核心概念
状态(state):AQS通过一个整型变量state来表示同步状态。不同的同步器可以根据自己的需求定义state的含义,例如对于独占锁,state可以表示锁的持有状态;对于共享锁,state可以表示可用资源的数量。
独占模式(Exclusive Mode):独占模式下,只有一个线程能获取同步状态,其他线程必须等待。例如,ReentrantLock就是基于独占模式实现的。
共享模式(Shared Mode):共享模式下,多个线程可以同时获取同步状态。例如,Semaphore和CountDownLatch就是基于共享模式实现的。
等待队列(Wait Queue):AQS内部维护一个FIFO等待队列,用于管理被阻塞的线程。当线程获取同步状态失败时,会被加入到等待队列中,等待其他线程释放同步状态后被唤醒。
每个节点(Node)代表一个等待的线程,节点之间通过 next 和 prev 指针链接。
static final class Node {
static final Node SHARED = new Node();
static final Node EXCLUSIVE = null;
...
volatile int waitStatus;
volatile Node prev;
volatile Node next;
volatile Thread thread; // 保存等待的线程
Node nextWaiter;
...
}AQS的工作原理
AQS通过以下几个核心方法来实现同步器的功能:
- acquire(int arg):以独占模式获取同步状态,如果获取失败,则将当前线程加入等待队列,并阻塞直到同步状态可用。
- release(int arg):以独占模式释放同步状态,唤醒等待队列中的下一个线程(如果有)。
- acquireShared(int arg):以共享模式获取同步状态,如果获取失败,则将当前线程加入等待队列,并阻塞直到同步状态可用。
- releaseShared(int arg):以共享模式释放同步状态,唤醒等待队列中的所有线程(如果有)。
- tryAcquire(int arg):尝试以独占模式获取同步状态,返回true表示获取成功,返回false表示获取失败。需要由具体的同步器实现。
- tryRelease(int arg):尝试以独占模式释放同步状态,返回true表示释放成功,返回false表示释放失败。需要由具体的同步器实现。
- tryAcquireShared(int arg):尝试以共享模式获取同步状态,返回大于等于0的值表示获取成功,返回负值表示获取失败。需要由具体的同步器实现。
- tryReleaseShared(int arg):尝试以共享模式释放同步状态,返回true表示释放成功,返回false表示释放失败。需要由具体的同步器实现。
AQS实现一个简单的独占锁
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
public class SimpleLock {
private final Sync sync = new Sync();
private static class Sync extends AbstractQueuedSynchronizer {
@Override
protected boolean tryAcquire(int arg) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
@Override
protected boolean tryRelease(int arg) {
if (getState() == 0) {
throw new IllegalMonitorStateException();
}
setExclusiveOwnerThread(null);
setState(0);
return true;
}
@Override
protected boolean isHeldExclusively() {
return getState() == 1;
}
}
public void lock() {
sync.acquire(1);
}
public void unlock() {
sync.release(1);
}
public boolean isLocked() {
return sync.isHeldExclusively();
}
}- tryAcquire(int arg)方法尝试获取锁,通过CAS操作将state从0设置为1。
- tryRelease(int arg)方法释放锁,通过将state设置为0并清除当前线程的持有状态。
- lock()方法通过调用acquire(1)获取锁。
- unlock()方法通过调用release(1)释放锁。
- isLocked()方法检查当前锁是否被持有。
谈谈你对CAS的理解?Compare-And-Swap
口语化
CAS是Java中Unsafe类里面的一个方法,全称是Compare-And-Swap,比较并交换的意思。 它的主要功能是保证在多线程的环境下对共享变量修改的原子性。用于实现无锁并发。
CAS避免了传统锁机制带来的上下文切换开销。
CAS是一种硬件级别的原子操作,它比较内存中的某个值是否为 预期值,如果是,则更新为新值,否则不做修改
相关说明:
CAS的原子性由操作系统保证,但系统层面也是读取和更新两个操作,如果是在多核CPU的情况下,操作系统会为其添加lock指令对缓存或总线加锁,以确保原子性
CAS主要是应用在一些高并发的场景中,有两个常用场景。
一:JUC中的Atomic包里的原子类实现,AtomicInteger、AtomicLong等
二:多线程对共享资源竞争的互斥性质,例如AQS、ConcurrentHashMap、ConcurrentLinkedQueue
以上
CAS的工作原理
CAS操作涉及三个操作数:
内存位置(V):需要操作的变量的内存地址。
预期值(E):期望变量的当前值。
新值(N):希望将变量更新为的新值。
CAS操作的步骤如下:
读取变量的当前值。
比较(Compare):比较变量的当前值与预期值(E)。
交换(Swap):如果当前值等于预期值,则将变量更新为新值(N),并返回true,表示更新成功。
失败重试:如果当前值不等于预期值,说明有其他线程已经修改了该值,CAS操作失败,一般会利用重试(自旋),直到成功。
CAS的优点
无锁操作:CAS是无锁操作,不需要加锁,从而避免了锁带来的开销和潜在的死锁问题。
高性能:在高并发环境中,CAS操作的性能通常优于加锁机制,因为它减少了线程的阻塞和上下文切换。
原子性:CAS操作是原子的,即使在多线程环境中,也能确保操作的正确性。
CAS的缺点
ABA问题:CAS操作可能会遇到ABA问题,即变量在检查和更新之间被其他线程多次修改,但最终值看起来没有变化。可以通过增加版本号或使用AtomicStampedReference来解决。
自旋等待:CAS操作在失败时通常会自旋重试,这可能会导致CPU资源的浪费,尤其是在高冲突场景下。
单变量限制:CAS操作仅适用于单个变量的更新,不适用于涉及多个变量的复杂操作
CAS在Java中的应用
Java提供了一些基于CAS操作的并发类,例如AtomicInteger、AtomicBoolean、AtomicReference等。它们使用CAS操作来实现原子性更新,避免了显式加锁。
import java.util.concurrent.atomic.AtomicInteger;
//AtomicInteger类使用CAS操作来实现原子性递增操作,确保在多线程环境下操作的正确性。
public class CASExample {
private AtomicInteger atomicInteger = new AtomicInteger(0);
public void increment() {
int oldValue, newValue;
do {
oldValue = atomicInteger.get();
newValue = oldValue + 1;
} while (!atomicInteger.compareAndSet(oldValue, newValue));
}
public int getValue() {
return atomicInteger.get();
}
public static void main(String[] args) {
CASExample example = new CASExample();
example.increment();
System.out.println("Value: " + example.getValue());
}
}下面使用CAS优化的案例
public class Example {
private int state = 0;
public void doSomething() {
if(state == 0) { // 多线程环境下存在原子性问题
state = 1;
// ...
}
}
}这个方法的逻辑在单线程的环境下没有问题,但是在多线程的环境下会存在原子性问题。这是一个典型的READ-Wtiter的操作。一般情况下,我们会在方法上加上synchronized关键字来解决原子性问题,但是加同步锁一定会带来性能上的损耗,所以对于性能要求较高的场景,我们可以使用CAS机制来进行优化。
优化后
public class Example {
private volatile int state = 0;
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long stateOffset;
static {
try {
stateOffset = unsafe.objectFieldOffset(Example.class.getDeclaredField("state"))
} catch (Exception e){
...
}
}
public void doSomething() {
if(unsafe.compareAndSwapInt(this, stateOffset, 0, 1)) {
// ...
}
}
}Unsafe
Unsafe是CAS的核心类,由于Java方法无法直接访问底层操作系统,需要通过本地(native)方法来访问,Unsafe相当于一个后门,基于该类可以直接操作特定内存的数据。
Unsafe类存在于sum.misc包中,其内部方法操作可以像C语言的指针一样直接操作内存,因为Java中CAS操作的执行依赖于Unsafe类的方法。
注意:Unsafe类中的所有方法都是native修饰的,也就是Unsafe类中的方法都直接调用操作系统底层资源执行相应任务。
AtomicInteger类是CAS的典型实现,其内部使用的是Unsafe类
/**
* Atomically increments by one the current value.
*
* @return the previous value
*/
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}说明:
变量valueOffset,表示该变量值在内存中的偏移地址,因为Unsafe就是根据内存偏移地址获取数据的。
// AtomicInteger类
private volatile int value;说明:
变量value用volatile修饰,保证了多线程之间的内存可见性。
CAS并发原语体现在Java语言中就是sum.misc.Unsafe类中的各个方法。调用Unsafe类中的CAS方法,JVM会帮我们实现CAS汇编指令。这是一种完全依赖于硬件的功能,通过它实现了原子操作。
再次调用,CAS是一种系统原语。
原语属于操作系统用语范畴,是由若干条指令组成的,用于完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,也就是说CAS是一条CPU的原子指令,不会造成所谓的数据不一致问题。
CAS的缺点?
循环时间长开销很大
// Unsfafe.class
public final int getAndSetInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var4));
return var5;
}我们可以看到 getAndSetInt 方法有个 do-while 逻辑。如果CAS失败,会一直进行尝试。如果CAS长时间不成功,会形成CPU资源浪费。
ABA问题
ABA问题是并发编程中的一种常见问题,通常出现在使用乐观锁或无锁算法(如CAS操作)的场景下。它描述了一种潜在的竞争条件,可能导致程序逻辑错误。
在多线程环境中,CAS(Compare-And-Swap)是一种常用的原子操作,用于实现线程安全的操作。其基本逻辑是:
- 比较内存中的值是否等于预期值。
- 如果相等,则将内存中的值替换为新值;否则不进行替换。
然而,CAS操作存在一个隐含的问题:如果某个值从A变为B,再变回A,那么CAS操作可能会误认为该值从未被修改过,从而导致逻辑错误。
示例:
假设有一个共享变量value,初始值为A,多个线程对其操作:
1、线程1读取到value = A,准备执行CAS操作。
2、在线程1执行CAS之前,线程2将value修改为B,然后又改回A。
3、线程1执行CAS时发现value仍然是A,于是成功执行了CAS操作。
尽管CAS操作看似成功,但实际上value可能已经被其他线程修改过多次,这会导致逻辑上的错误
解决方案
1)引入版本号
在数据结构中增加一个版本号字段,每次修改数据时递增版本号。这样即使值从A变回A,版本号也会不同,从而避免误判。
2)使用带有时间戳的CAS
通过记录时间戳或序列号,确保即使值相同,也能区分出不同的修改。
3)使用AtomicStampedReference
Java中提供了AtomicStampedReference类,专门用于解决ABA问题。它通过引入一个额外的“标记”(stamp)来区分相同的值。
import java.util.concurrent.atomic.AtomicStampedReference;
public class ABADemo {
private static AtomicStampedReference<Integer> atomicRef =
new AtomicStampedReference<>(1, 0);
public static void main(String[] args) {
int[] stampHolder = {atomicRef.getStamp()};
// 线程1尝试修改值
new Thread(() -> {
int stamp = atomicRef.getStamp();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
boolean success = atomicRef.compareAndSet(1, 2, stamp, stamp + 1);
if (success) {
System.out.println("Thread 1: Modified value to 2");
}
success = atomicRef.compareAndSet(2, 1, atomicRef.getStamp(), atomicRef.getStamp() + 1);
if (success) {
System.out.println("Thread 1: Modified value back to 1");
}
}).start();
// 线程2尝试修改值
new Thread(() -> {
boolean success = atomicRef.compareAndSet(1, 3, stampHolder[0], stampHolder[0] + 1);
if (success) {
System.out.println("Thread 2: Successfully modified value to 3");
} else {
System.out.println("Thread 2: Modification failed due to ABA problem");
}
}).start();
}
}4)使用锁机制
虽然锁会降低性能,但可以完全避免ABA问题,因为锁确保同一时间只有一个线程能修改共享资源。
什么是自旋锁?自旋锁的优缺点
自旋锁(Spin Lock) 是一种轻量级的锁机制,主要用于多线程环境下的同步控制。
与传统的互斥锁(如mutex)不同,自旋锁不会让线程在等待锁时进入阻塞状态,而是通过循环不断检查锁的状态,直到锁被释放。
工作原理
当一个线程尝试获取锁时,如果锁已经被其他线程占用,则该线程会进入一个循环(称为“自旋”),持续检查锁是否可用。
一旦锁被释放,当前线程立即获取锁并继续执行。
如果锁始终不可用,线程会一直循环检查,直到锁被释放。
伪代码:
int lock = 0; // 0表示未加锁,1表示已加锁
void spin_lock() {
while (__sync_lock_test_and_set(&lock, 1)) { // 尝试设置锁
// 锁已被占用,继续自旋
}
// 获取锁成功
}
void spin_unlock() {
__sync_lock_release(&lock); // 释放锁
}由伪代码可知,CAS是实现自旋锁的基础
特点
(1)优点
- 低延迟:对于短时间的锁持有,自旋锁可以避免线程切换带来的开销,从而提高性能。
- 简单高效:实现简单,适合高并发、锁竞争时间短的场景。
(2)缺点
- 浪费CPU资源:如果锁长时间不可用,线程会一直占用CPU进行循环检查,导致资源浪费。
- 不适合长时间锁持有:如果锁被占用的时间较长,自旋锁会导致不必要的CPU消耗。
适用场景
- 锁竞争时间短:例如,保护一小段临界区代码,且预计锁很快会被释放。
- 多核处理器环境:在多核系统中,自旋锁可以充分利用多个CPU核心的优势,减少上下文切换的开销。
- 实时系统:需要快速响应的场景,避免线程阻塞带来的延迟。
改进版:自适应自旋锁
为了减少CPU资源浪费,许多现代系统实现了自适应自旋锁:
- 如果锁预计很快会被释放,则线程会短暂地自旋。
- 如果锁长时间不可用,则线程会进入阻塞状态,交出CPU资源。
总结
自旋锁是一种高效的同步机制,但需要根据具体场景选择使用。对于锁持有时间较短的场景,自旋锁可以显著提升性能;而对于锁持有时间较长的场景,则应考虑使用传统的互斥锁或其他同步机制,以避免浪费CPU资源。
自旋锁时间阈值
什么是可重入锁(递归锁)?
可重入锁(Reentrant Lock)是指同一个线程可以多次获取同一把锁,而不会导致死锁的情况。也就是说,已经持有锁的线程可以再次获取该锁而不被阻塞。
解释:指在同一个线程的外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提是锁对象是同一个对象),不会因为之前已经获取过还没释放而阻塞。
例如:有一个 synchronized 修饰的递归调用方法,程序第二次进入被自己阻塞了岂不是天大的笑话,出现了作茧自缚。
特性:
- 可重入性:同一个线程可以多次获取同一把锁,并且每次获取锁时都需要释放相同次数的锁才能完全释放该锁。
- 持有者信息:可重入锁会记录哪个线程持有锁以及持有锁的次数。
- 公平性选择:可重入锁通常提供公平锁和非公平锁的选择,允许开发者根据需求配置。
应用场景:
- 递归调用:当一个方法内部调用另一个需要同步的方法时,使用可重入锁可以避免死锁。
- 复杂的同步逻辑:在多层嵌套的同步代码中,可重入锁确保同一线程不会因为重复进入同步块而被阻塞。
Java 中的可重入锁
- 隐式锁(即synchronized关键字使用的锁 )默认是可重入锁
- 显式锁(即 Lock)ReentrantLock
示例
import java.util.concurrent.locks.ReentrantLock;
public class ReentrantLockExample {
private final ReentrantLock lock = new ReentrantLock();
public void method1() {
lock.lock();
try {
// 执行一些操作
System.out.println("Method1 acquired the lock.");
method2(); // 递归调用 method2
} finally {
lock.unlock();
}
}
public void method2() {
lock.lock();
try {
// 执行一些操作
System.out.println("Method2 acquired the lock.");
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
ReentrantLockExample example = new ReentrantLockExample();
example.method1();
}
}总结
可重入锁允许同一个线程多次获取同一把锁,从而避免了死锁问题,并且提供了更灵活的同步机制。在 Java 中,ReentrantLock 是常用的可重入锁实现。
ReentrantLock和synchronized的区别?
synchronized 是Java的关键字,用于实现基本的同步机制,非公平、不支持超时、不可中断、不支持多条件。
ReentrantLock 是JUC提供的一个类,JDK1.5引入,支持设置超时,可以避免死锁,支持公平锁、可被中断、支持多条件判断。
ReentrantLock 需要手动解锁;而synchronized 不需要,它们都是可重入锁。
性能问题:早期的JDK版本中,synchronized 性能不如 ReentrantLock,但现在基本上性能是差不多的
锁的获取方式
synchronized:- 是一种内置的关键字,使用简单,语法上直接加在方法或代码块上。
- 自动管理锁的获取和释放,不需要显式调用。
ReentrantLock:- 是一个显式的锁对象,需要通过
new ReentrantLock()创建。 - 需要显式调用
lock()获取锁和unlock()释放锁。
- 是一个显式的锁对象,需要通过
公平性
synchronized:不支持公平锁,默认是非公平的,即不保证等待时间最长的线程优先获取锁。ReentrantLock:支持公平锁和非公平锁(默认是非公平的)
ReentrantLock lock = new ReentrantLock(); // 非公平锁
ReentrantLock lock = new ReentrantLock(true); // 公平锁锁的中断
synchronized:不支持锁中断,一旦线程进入等待状态,无法通过Thread.interrupt()中断。ReentrantLock:支持锁中断,可以使用tryLock(long timeout, TimeUnit unit)尝试获取锁,并且可以在等待时响应中断,有效避免死锁
锁的超时
synchronized:不支持超时机制,如果无法获取锁,线程会一直等待。ReentrantLock:支持超时机制,可以使用tryLock(long timeout, TimeUnit unit)在指定时间内尝试获取锁,超时后返回false。
性能
synchronized:在JDK 6之后进行了大量优化,性能已经接近甚至超过ReentrantLock,特别是在争用较少的情况下。ReentrantLock:提供了更灵活的控制,但在某些情况下可能会比synchronized稍慢,尤其是在争用激烈的情况下。
扩展
synchronized 性能优化
synchronized在JDK1.6之后进行了很多性能优化,主要包括如下:
- 偏向锁:如果一个锁被同一个线程多次获得,JVM会将该锁设置为偏向锁,以减少获取锁的代价
- 轻量级锁:如果没有线程竞争,JVM会将锁设置为轻量级锁,使用CAS操作代替互斥同步
- 锁粗化(锁膨胀):JVM会将一些短时间内连续的锁操作合并为一个锁操作,以减少锁操作的开销
- 锁消除:JVM在JIT编译时会检测到一些没有竞争的锁,并将这些锁去掉,以减少同步的开销
锁的状态查询
synchronized:没有提供API来查询当前锁的状态。ReentrantLock:提供了丰富的API来查询锁的状态,如isHeldByCurrentThread()、getHoldCount()等。
什么是可重入锁及使用场景?
可重入锁实现原理
锁升级机制是怎样的
常用的锁都有哪些,适用的场景
Lock常用的实现类?
Locak的实现方法?
ReentrantLock的实现
Semaphore信号量的使用
synchronized同步锁有哪几种方法?
同步方法:synchronized 关键字直接修饰方法,表示同一时刻只有一个线程能进入这个方法,其他线程在外面等着。
基本格式:
修饰符 synchronized 返回值类型 method(形参列表){
// 可能会产生线程安全问题的代码
}同步代码块:它提供了更细粒度的控制,只对特定的代码块进行同步,而不是整个方法。这可以减少锁的竞争,提高程序的性能。
基本格式:
synchronized(同步锁){
// 需要同步操作的代码
}如何选择同步锁对象?如何设定同步代码访问?
同步锁对象可以是任意类型,但是必须保证竞争”同一个共享资源”的多个线程必须使用同一个“同步锁对象”。
对于同步方法来说,同步锁对象只能是默认的:
- 静态方法:当前类的 Class 对象(类名.class)
- 非静态方法:this
对于同步代码块来说,同步锁对象是由程序员手动指定的(很多时候也是指定为 this 或类名.class)
同步代码块不是越大越好,否则会导致性能低下,或者其他线程没有机会。也不是越小越好,否则安全问题无法彻底解决。具体以单次原子性任务代码为准。
Java中的synchronized是怎么实现的?(底层原理)
synchronized关键字的实现是基于监视器锁(Monitor)。监视器锁是一个互斥锁,确保同一时间只有一个线程可以持有锁并执行同步代码块或方法。
每个Java对象都有一个对象头,其中包含对象的元数据信息,包括锁信息。对象头中的锁状态可以是无锁状态、偏向锁、轻量级锁和重量级锁。
在Java中,synchronized关键字的锁状态会根据竞争情况动态转换,主要包括以下几种状态:
- 无锁状态:没有线程竞争锁
- 偏向锁:当一个线程访问同步块时,JVM会将锁偏向该线程,减少锁的开销
- 因为不存在竞争关系,所以将锁资源偏向某一线程,该线程再次进入时,无锁
- 轻量级锁(有一种说法也叫自旋锁):当多个线程竞争锁时,JVM会尝试使用自旋锁,避免线程上下文切换的开销
- 在线程阻塞之前会进行自旋尝试获取锁,如果其他线程释放锁,可能能够抢到锁资源
- 重量级锁:当自旋锁失败时,JVM会将锁升级为重要级锁,使用操作系统提供的互斥锁
扩展
锁消除/锁膨胀:这是编译器层面的优化
锁消除:编译时发现你锁的地方不存在竞争,会消除锁
锁膨胀:表示的是你控制的锁粒度太小了,导致频繁的加锁、释放锁,频繁的竞争资源,编译器会将锁的范围扩大
synchronized是可重入锁吗?它的重入实现原理?
是的,synchronized 默认情况下是可重入锁。这意味着如果一个线程已经持有了某个对象的锁,那么它可以在不释放这个锁的情况下再次获取该锁,而不会导致死锁
重入实现原理
- 对象头中的锁信息:
- 在 Java 中,每个对象都有一个对象头(Object Header),其中包含了一部分用于同步的信息,比如锁状态、线程ID等。
- Monitor机制:
synchronized的底层实现依赖于 JVM 内部的数据结构——Monitor(监视器)。Monitor中有一个计数器,用来记录当前持有锁的次数,以及一个指向持有锁的线程的引用。
- 锁获取流程:
- 当一个线程尝试进入由
synchronized保护的方法或代码块时,它会检查 Monitor 中的线程引用是否为 null 或者是否与自己相同。 - 如果是第一次获取锁,Monitor 记录下当前线程,并将计数器设为1;如果是同一个线程再次获取锁,则计数器加1。
- 线程每次退出
synchronized代码块时,计数器减1,当计数器归零时,表示该线程完全释放了锁,其他等待的线程可以尝试获取锁。
- 当一个线程尝试进入由
- 字节码指令:
- 在编译后的字节码中,
synchronized关键字会被转换成monitorenter和monitorexit指令,分别对应获取和释放锁的操作。
- 在编译后的字节码中,
- 优化措施:
- JVM 对
synchronized进行了许多优化,如偏向锁、轻量级锁和重量级锁的状态转换,以提高性能。这些优化使得在大多数情况下,synchronized的性能非常接近显式锁(如ReentrantLock),并且在某些场景下甚至更优
- JVM 对
每个锁对象拥有一个锁计数器和一个指向持有锁的线程的指针。
当指向
monitorenter时,如果目标锁对象的计数器为0,那么说明它没有被其他线程所持有,Java虚拟机会将该锁对象的持有线程设置为当前线程,并且将其计数器+1。在目标锁对象的计数器不为0的情况下,如果锁对象的持有线程是当前线程,那么Java虚拟机可以将其计数器+1,否则需要等待,直至持有线程释放该锁。
当执行
monitorexit时,Java虚拟机则需将锁对象的计数器-1。计数器为0代表锁已被释放。
synchronized能否被打断,什么情况下打断
synchronized的不同作用范围有什么区别
为什么wait和notify必须要在synchronized代码块使用?
Java中的synchronized轻量级锁是否会进行自旋?
Java中的synchronizeds升级到重量级锁时,会发生什么?
什么是Java中的锁自适应自旋?
lock和synchronized的区别?
线程池的异步任务执行完后,如何回调
你理解Java线程池原理吗?
你的项目中是如何使用线程池的?
如何设置Java线程池的线程数(实际工作中)?
Java线程池有哪些拒绝策略?
如何优化Java中的锁?
线程池如何知道一个线程的任务已经执行完毕了?(小米)
Java并发库中提供了哪些线程池实现?它们有什么区别?
Java中的Delay和ScheduledThreadPool有什么区别?
什么是Java的Timer?
什么叫做阻塞队列的有界和无解?
讲一下wait和notify为什么要在synchronized代码块中?
ReadWriteLock的整体实现
Lock的公平锁与非公平锁
为什么会有公平锁与非公平锁的设计?为什么要默认非公平?
- 公平锁与非公平锁的设计原因:
- 公平锁确保线程按照请求锁的顺序获得锁,避免线程饥饿问题。适用于对实时性要求较高的场景。
- 非公平锁允许后来的线程“插队”获取锁,若锁恰好可用。这能减少上下文切换,提高吞吐量。
- 默认非公平的原因:
- 非公平锁在大多数情况下性能更优,因为它减少了不必要的阻塞和唤醒操作。
- 实际应用中,线程饥饿的情况较为罕见,而非公平锁带来的性能提升更为显著。
- 默认采用非公平锁可以为开发者提供更好的性能体验,同时仍允许根据需求选择公平锁。
什么时候用公平锁?什么时候用非公平锁?
- 使用公平锁的场景:
- 实时性要求高:当系统中某些任务对响应时间有严格要求,必须按照请求顺序执行时,应使用公平锁。
- 避免线程饥饿:在多线程环境中,若存在大量竞争且某些线程长期无法获取锁资源,使用公平锁可以确保每个线程最终都能获得锁。
- 特定业务逻辑需求:例如银行转账等金融交易系统,可能需要严格按照请求顺序处理事务,以保证数据一致性。
- 使用非公平锁的场景:
- 性能优先:大多数情况下,非公平锁能提供更高的吞吐量和更低的延迟,适用于对性能敏感的应用。
- 线程饥饿风险低:如果系统中的线程数量较少或竞争不激烈,选择非公平锁可以在不影响公平性的前提下提高效率。
- 无严格顺序要求:当业务逻辑不要求严格的执行顺序,允许一定程度上的随机性时,非公平锁是更好的选择。
总结
当需要更高的吞吐量和更低的延迟情况下,使用非公平锁比较合适,可以节省很多线程切换时间
否则就可以使用公平锁(不存在线程饥饿)
AtomicInteger的实现方式及场景
你了解时间轮(Time Wheel)吗?他在Java中有哪些应用场景?
你使用过哪些Java并发工具?
你使用过Java中哪些原子类?
你使用过Java中的累加器吗?
什么是守护线程?他有什么特点?
reentrantLock是如何实现公平锁和非公平锁?
reentrantLock的实现原理?
你了解Java中的读写锁吗?
如何优化Java中的锁?
什么是Java的Semaphore?
什么是Java的CycliBarrier?
什么是Java的CountDownLatch?countdownLatch用法
什么是Java的CyclicBarrier?CyclicBarrier用法?
什么是Java的StampedLock?
什么是FutureTask?
什么是Java的CompletableFuture?
CompletableFuture 是 Java 8 引入的一个类,位于 java.util.concurrent 包中。它是对 Future 接口的增强版本,提供了更强大的异步编程能力,并支持函数式编程风格。
通过 CompletableFuture,可以更方便地处理异步任务的结果、组合多个异步任务以及管理任务之间的依赖关系。
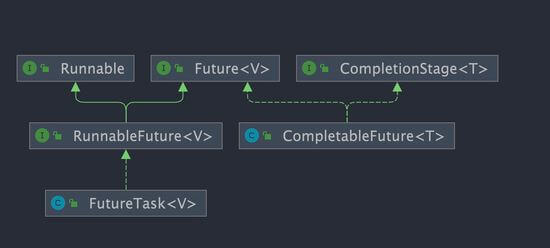
CompletableFuture 同时实现了 Future 和 CompletionStage 接口
CompletionStage 接口描述了一个异步计算的阶段。很多计算可以分成多个阶段或步骤,此时可以通过它将所有步骤组合起来,形成异步计算的流水线。
CompletionStage 接口中的方法比较多,CompletableFuture 的函数式能力就是这个接口赋予的
基本概念
- 异步执行:
CompletableFuture支持异步任务的创建和执行。 - 链式调用:可以通过链式调用的方式处理任务结果,避免了回调地狱(Callback Hell)。
- 组合任务:可以将多个异步任务组合在一起,形成复杂的任务流。
创建异步任务
CompletableFuture的四大静态方法:(用于创建 异步任务)
无返回值
- CompletableFuture<Void> runAsync(Runnable runnable)
- CompletableFuture<Void> runAsync(Runnable runnable, Executor executor)
有返回值
- CompletableFuture<U> supplyAsync(Supplier<U> supplier)
- CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)
executor参数说明:
若没有指明,则使用ForkJoinPool.commonPool()作为线程池执行异步代码
建议给出,达到线程池隔离的目的
如果使用默认线程池commonPool,当main线程结束时,线程池会 立刻 关闭,导致异步任务无法执行
因此
1.需要保证main线程在 所有异步任务之后 结束 或者2.使用自定义线程池
不建议通过new 创建CompletableFuture
CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> {
System.out.println("Running async task without result");
});
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> {
return "Hello, CompletableFuture!";
});处理任务结果
- thenApply(Function<? super T, ? extends U> fn):对任务结果进行转换。
- 对计算结果进行处理(计算结果存在依赖关系,这两个线程串行化)
- 异常相关:由于存在依赖关系(当前出错,就不会进行下一步操作了),当前步骤有异常的话就会立即叫停
- thenAccept(Consumer<? super T> action):对任务结果进行消费,但不产生新的结果
- 对计算结果进行消费(接收任务的处理结果,并消费处理,无返回结果)
- thenRun(Runnable action):在任务完成后执行一个无参数的操作,即不需要使用上一个任务的结果
then*:在上一个异步任务执行完,然后执行本任务
then*Async:默认会利用ForkJoinPool.commonPool来执行任务
| 方法 | 示例 |
|---|---|
| thenRun | 任务A执行完毕执行B,并且B不需要A的结果 |
| thenAccept | 任务A执行完毕执行B,B需要A的结果,但是任务B无返回值 |
| thenApply | 任务A执行完毕执行B,B需要A的结果,同时任务B有返回值 |
示例:
System.out.println(CompletableFuture.supplyAsync(() -> "result-A")
.thenRun(() -> {
}).join()
); // join 获取的结果为null
System.out.println(CompletableFuture.supplyAsync(() -> "result-A").thenAccept((r) -> {
System.out.println(r); // result-A
}).join()); // join 获取的结果为null,因为thenAccept无返回值
System.out.println(CompletableFuture.supplyAsync(() -> "result-A").thenApply((r) -> {
return r + "-result-B";
}).join()); // join 获取的结果为result-A-result-B异常处理
- exceptionally:处理任务中的异常。
- handle:无论是否发生异常,都会执行。
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
throw new RuntimeException("Error occurred!");
}).exceptionally(ex -> {
return "Recovered from exception: " + ex.getMessage();
});
future.thenAccept(System.out::println); // 输出恢复后的结果组合多个任务
- thenCombine:合并两个任务的结果。
- thenAcceptBoth:对两个任务的结果进行消费。
- applyToEither:选择第一个完成的任务的结果(对计算速度进行选用)
- thenCompose: 按顺序执行两个并行任务(将任务A的结果作为任务B的输入)
CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() -> "Hello");
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> "World");
CompletableFuture<String> combinedFuture = future1.thenCombine(future2, (result1, result2) -> result1 + " " + result2);
combinedFuture.thenAccept(System.out::println); // 输出 "Hello World"等待所有任务完成
- allOf:等待所有任务完成。
- anyOf:等待任意一个任务完成。
CompletableFuture<Void> allFutures = CompletableFuture.allOf(
CompletableFuture.runAsync(() -> System.out.println("Task 1")),
CompletableFuture.runAsync(() -> System.out.println("Task 2")),
CompletableFuture.runAsync(() -> System.out.println("Task 3"))
);
allFutures.join(); // 等待所有任务完成阻塞操作
- get():阻塞等待结果
- get(long timeout, TimeUnit unit) 超时等待结果
- join():阻塞等待结果
- getNow(T valueIfAbsent) 立即获取结果(不阻塞),如果任务未完成(未获取到结果),则返回valueIfAbsent
String result = CompletableFuture.supplyAsync(() -> "Result").join();
System.out.println(result); // 输出 "Result"与Future的区别
Future是JDK5引入的接口,提供了基本的异步处理功能,它的一个重要实现类是FutureTask,主要用于异步执行任务并获取任务的结果。但它的局限性在于只能通过get()方法阻塞的获取结果,无法链式调用,也缺少异常处理机制。
Future的优缺点
- 优点:future+线程池 异步多线程任务配合,显著提高程序的执行效率
- 缺点:
- get()阻塞
- isDone()轮询,耗费无谓的CPU资源
CompletableFuture是Future的增强版,提供了非阻塞的结果处理、任务组合和异常处理,使得异步编程变得更加灵活强大
一个任务需要依赖另外两个任务执行完之后再执行,怎么设计?
这种任务编排场景非常适合通过CompletableFuture实现。这里假设要实现 T3 在 T2 和 T1 执行完后执行。
示例:
CompletableFuture.allOf
// 定义两个异步任务
CompletableFuture<String> task1 = CompletableFuture.supplyAsync(() -> {
System.out.println("Task 1 is running...");
return "Result from Task 1";
});
CompletableFuture<String> task2 = CompletableFuture.supplyAsync(() -> {
System.out.println("Task 2 is running...");
return "Result from Task 2";
});
// 等待 task1 和 task2 都完成后执行后续任务
CompletableFuture<Void> allTasks = CompletableFuture.allOf(task1, task2);
// 后续任务
allTasks.thenRun(() -> {
System.out.println("Both Task 1 and Task 2 are completed.");
try {
// 获取 task1 和 task2 的结果
String result1 = task1.get();
String result2 = task2.get();
System.out.println("Task 1 Result: " + result1);
System.out.println("Task 2 Result: " + result2);
} catch (Exception e) {
e.printStackTrace();
}
});thenCombine :合并两个任务的结果
// 定义两个异步任务
CompletableFuture<String> task1 = CompletableFuture.supplyAsync(() -> {
System.out.println("Task 1 is running...");
return "Hello";
});
CompletableFuture<String> task2 = CompletableFuture.supplyAsync(() -> {
System.out.println("Task 2 is running...");
return "World";
});
// 后续任务依赖 task1 和 task2 的结果
CompletableFuture<String> combinedTask = task1.thenCombine(task2, (result1, result2) -> {
return result1 + " " + result2;
});
// 输出最终结果
combinedTask.thenAccept(result -> {
System.out.println("Combined Result: " + result); // 输出 "Hello World"
});在使用 CompletableFuture 的时候为什么要自定义线程池?
CompletableFuture 默认使用全局共享的 ForkJoinPool.commonPool() 作为执行器,所有未指定执行器的异步任务都会使用该线程池。这意味着应用程序、多个库或框架(如 Spring、第三方库)若都依赖 CompletableFuture,默认情况下它们都会共享同一个线程池。
虽然 ForkJoinPool 效率很高,但当同时提交大量任务时,可能会导致资源竞争和线程饥饿,进而影响系统性能。
为避免这些问题,建议为 CompletableFuture 提供自定义线程池,带来以下优势:
- 隔离性:为不同任务分配独立的线程池,避免全局线程池资源争夺。
- 资源控制:根据任务特性调整线程池大小和队列类型,优化性能表现。
- 异常处理:通过自定义
ThreadFactory更好地处理线程中的异常情况
什么是Java的ForkJoinPool?
Java的ForkJoinPool是JDK 7引入的一个专门用于并行执行任务的线程池,它采用”分而治之“算法来解决大规模的并行问题。
核心机制:
1、Fork(分解):任务被递归分解为更小的子任务,直到达到不可再分的程序
2、Join(合并):子任务执行完毕后,将结果合并,形成最终的解决方案
工作窃取算法:ForkJoinPool使用了一种称为工作窃取的调度算法。空闲的工作线程会从其他繁忙线程的工作队列中”窃取“未完成的任务以保持资源高效利用
关键类:
ForkJoinPool:表示Fork/Join框架中的线程池。ForkJoinTask:任务的基础抽象类,子类有:RecursiveTask、Recursivection,分别用于有返回值和无返回值任务
ForkJoinPool与普通线程池的区别
- 任务分解与合并:穿透的线程池一般处理相对独立的任务,而ForkJoinPool则擅长处理可以分解的任务,最终将结果进行合并
- 线程调度策略:ForkJoinPool中的每个工作线程都维护着自己的双端队列,并通过工作窃取来平衡任务,而普通线程池通常由中央队列来管理任务
ForkJoinPool与并行流的关系
Java 8中的并行流(Parallel Streams)底层正是基于ForkJoinPool实现的,通过paralleStream()方法,可以轻松的利用ForkJoinPool来实现并行操作,从而提高处理效率。
Java中如何控制多个线程的执行顺序?
CompletableFuture,例如thenRun,假设t1、t2、t3任务要按顺序执行,就可以使用thenRun方法
synchronized + wait/notify,通过对象锁和线程间通信机制来控制线程的执行顺序
ReentrantLock + condition
Thread类的join方法,通过调用这个方法,可以使得一个线程等待另一个线程执行完毕后再继续执行
CountDownLatch,使一个或线程等待其他线程完成各自工作后再继续执行
CyclicBarrier,是多个线程互相等待,直到所有线程都到达某个共同点后再继续执行
Semaphore,控制线程的执行顺序,适用于需要限制同时访问资源的线程数量的场景
线程池,单个线程的线程池,按序的将任务提交到线程池即可
程序、进程、线程?
程序(program)
为完成特定任务,用某种语言编写的一组指令的集合。即指一段静态的代码,静态对象。
进程(process)
程序的一次执行过程,或是正在内存中运行的应用程序。如:运行中的 QQ,运行中的网易音乐播放器。
- 每个进程都有一个独立的内存空间,系统运行一个程序即是一个进程从创建、运行到消亡的过程。(生命周期)
- 程序是静态的,进程是动态的
- 进程作为操作系统调度和分配资源的最小单位(亦是系统运行程序的基本单位),系统在运行时会为每个进程分配不同的内存区域。
- 现代的操作系统,大都是支持多进程的,支持同时运行多个程序。比如:现在我们上课一边使用编辑器,一边使用录屏软件,同时还开着画图板,dos 窗口等软件。
线程(thread)
进程可进一步细化为线程,是程序内部的一条执行路径。一个进程中至少有一个线程。
- 一个进程同一时间若并行执行多个线程,就是支持多线程的。
- 线程作为 CPU 调度和执行的最小单位。
- 一个进程中的多个线程共享相同的内存单元,它们从同一个堆中分配对象,可以访问相同的变量和对象。这就使得线程间通信更简便、高效。但多个线程操作共享的系统资源可能就会带来安全的隐患。
- 与进程相比,线程更加”轻量级“,创建、撤销一个线程比启动新进程的开销小得多
线程调度?
线程调度是操作系统的一项核心功能,它负责管理和分配处理器时间给多个线程。在多线程环境中,线程调度确保各个线程能够公平地获得CPU时间,并且在必要时能够进行上下文切换。以下是关于线程调度的一些基本概念和常见策略。
- 分时调度
所有线程轮流使用cpu的使用权,并且平均分配每个线程的使用时间
- 抢占式调度
让优先级高的线程以较大的概率优先使用 CPU。如果线程的优先级相同,那么会随机选择一个(线程随机性),Java使用的为抢占式调度。
并发与并行
并发(concurrency):指两个或多个事件在同一个时间段内发生。即在一段时间内,有多条指令在单个CPU上快速轮换、交替执行,使得在宏观上具有多个进程同时执行的效果。(微观上分时交替执行,宏观上同时进行)
比如:
小渣有五个女朋友,在某一天的上午7点到12点需要与五个女朋友约会,在7-8点他与女友A约会,8-9点他与女友B约会,9-10点他与女友C约会,10-11点他与女友D约会,11-12点他与女友E约会,他在一上午与5个女朋友约会了,在宏观上他就是在8-12点这段时间内与五个女朋友一起约会了。
并行(parallel):指两个或多个事件在同一时刻发生(同时发生)。指在同一时刻,有多条指令在多个CPU上同时执行。
比如:
小渣有五个女朋友,在某一天的上午7点到12点需要与五个女朋友约会,意思就是在7-12点这段时间(假设这是一个时刻)内要与五个女朋友一起约会,这就叫并行。(但是这在现实生活中肯定是不肯的,除非有五个小渣)
JDK1.5之前线程的五种状态
线程的生命周期有五种状态:新建(New)、就绪(Runnable)、运行 (Running)、阻塞(Blocked)、死亡(Dead)。CPU 需要在多条线程之间切换,于是线程状态会多次在运行、阻塞、就绪之间切换。
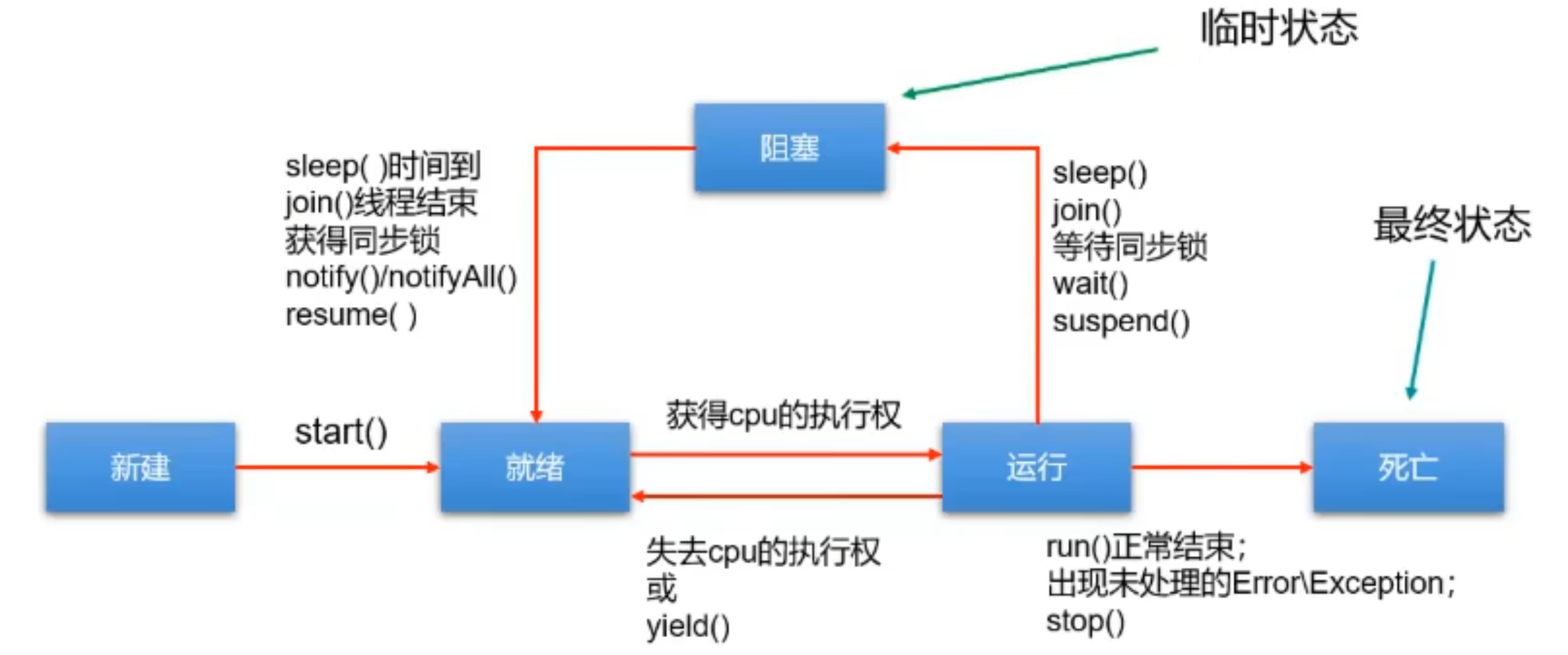
- 新建(New)
当一个 Thread 类或其子类的对象被声明并创建时,新生的线程对象处于新建状态。
此时它和其他 Java 对象一样,仅仅由 JVM 为其分配了内存,并初始化了实例变量的值。
此时的线程对象并没有任何线程的动态特征,程序也不会执行它的线程体 run()。
- 就绪(Runnable)
但是当线程对象调用了 start()方法之后,就不一样了,线程就从新建状态转为就绪状态。JVM 会为其创建方法调用栈和程序计数器,当然,处于这个状态中的线程并没有开始运行,只是表示已具备了运行的条件,随时可以被调度。至于什么时候被调度,取决于 JVM 里线程调度器的调度。
注意:
程序只能对新建状态(NEW)的线程调用 start(),并且只能调用一次,如果对非新建状态的线程,如已启动的线程或已死亡的线程调用 start()都会报错
IllegalThreadStateException异常。
- 运行 (Running)
如果处于就绪状态的线程获得了CPU资源时,开始执行 run()方法的线程体代码,则该线程处于运行状态。如果计算机只有一个 CPU 核心,在任何时刻只有一个线程处于运行状态,如果计算机有多个核心,将会有多个线程并行
(Parallel)执行。
当然,美好的时光总是短暂的,而且 CPU 讲究雨露均沾。对于抢占式策略的系统而言,系统会给每个可执行的线程一个小时间片来处理任务,当该时间用完,系统会剥夺该线程所占用的资源,让其回到就绪状态等待下一次被调度。
此时其他线程将获得执行机会,而在选择下一个线程时,系统会适当考虑线程的优先级。
- 阻塞(Blocked)
当在运行过程中的线程遇到如下情况时,会让出CPU并临时中止自己的执行,进入阻塞状态:
- 线程调用了 **sleep()**方法,主动放弃所占用的 CPU 资源;
- 线程试图获取一个同步监视器,但该同步监视器正被其他线程持有;
- 线程执行过程中,同步监视器调用了 wait(),让它等待某个通知(notify);
- 线程执行过程中,同步监视器调用了 wait(time)
- 线程执行过程中,遇到了其他线程对象的加塞(join);
- 线程被调用 suspend 方法被挂起(已过时,因为容易发生死锁);
当前正在执行的线程被阻塞后,其他线程就有机会执行了。针对如上情况,当发生如下情况时会解除阻塞,让该线程重新进入就绪状态,等待线程调度器再次调度它:
- 线程的 sleep()时间到;
- 线程成功获得了同步监视器;
- 线程等到了通知(notify);
- 线程 wait 的时间到了
- 加塞的线程结束了;
- 被挂起的线程又被调用了 resume 恢复方法(已过时,因为容易发生死锁);
- 死亡(Dead)
线程会以以下三种方式之一结束,结束后的线程就处于死亡状态:
- run()方法执行完成,线程正常结束
- 线程执行过程中抛出了一个未捕获的异常(Exception)或错误(Error)
- 直接调用该线程的 stop()来结束该线程(已过时)
JDK1.5之后线程的五种状态

在jdk1.5及之后线程有如下6种状态:
- NEW(新建)
该线程还没开始执行
- Runnable(可运行)
一旦调用start()方法,线程将处于Runnable状态,一个可运行的线程可能正在运行也可能还未运行,这取决于操作系统给线程提供运行的时间。
一旦一个线程开始运行,它不必始终保持运行。(因为操作系统的时间片轮转机制,目的是让其他线程获得运行的机会)线程调度的细节依赖于操作系统提供的服务。抢占式调度系统给每一个可运行的线程一个时间片来执行任务。时间片完,操作系统将剥夺线程的运行权
注意:
任何给定时刻,一个可运行的线程可能正在运行也可能没有运行(这就是为什么将这个状态称为可运行而不是运行)
Blocked(被阻塞)
当线程处于被阻塞或等待状态时,它暂不活动。他不允许任何代码且消耗最少的资源。
Waiting(等待)
Timed waiting(计时等待)
**Terminated(被终止)**线程被终止有如下两种原因:
- 因为run方法正常退出而自然死亡
- 因为一个没有捕获的异常终止了run方法而意外死亡
说明:
当从 WAITING 或 TIMED_WAITING 恢复到 Runnable 状态时,如果发现当前线程没有得到监视器锁,那么会立刻转入 BLOCKED 状态
特点强调,可以调用线程的**stop()方法(已过时)**杀死这个线程,但是该方法会抛出ThreadDeath错误对象,由此杀死线程。部分源码如下:
@Deprecated
public final void stop() {
SecurityManager security = System.getSecurityManager();
if (security != null) {
checkAccess();
if (this != Thread.currentThread()) {
security.checkPermission(SecurityConstants.STOP_THREAD_PERMISSION);
}
}
// A zero status value corresponds to "NEW", it can't change to
// not-NEW because we hold the lock.
if (threadStatus != 0) {
resume(); // Wake up thread if it was suspended; no-op otherwise
}
// The VM can handle all thread states
stop0(new ThreadDeath());
}
public class ThreadDeath extends Error {
private static final long serialVersionUID = -4417128565033088268L;
}可调用如下方法确定当前线程的状态
public State getState() // 得到线程的当前状态
// NEW,RUNNABLE,BLOCKED,WAITING,TIMED_WAITING,TERMINATED;在java.lang.Thread.State 的枚举类中这样定义:
public enum State {
/**
* Thread state for a thread which has not yet started.
线程状态为尚未启动的线程。
*/
NEW, // NEW(新建):线程刚被创建,但是并未启动。还没调用 start 方法。
/**
线程状态,用于可运行的线程。可运行的线程状态在Java虚拟机中执行,但可能正在等待操作系统的其他资源
如处理器。
*/
RUNNABLE, // RUNNABLE(可运行):这里没有区分就绪和运行状态。因为对于 Java 对象来说,只能标记为可运行,至于什么时候运行,不是 JVM 来控制的了,是 OS 来进行调度的,而且时间非常短暂,因此对于 Java 对象的状态来说,无法区分
// 重点说明,根据 Thread.State 的定义,阻塞状态分为三种:BLOCKED、WAITING、TIMED_WAITING
BLOCKED, // BLOCKED(锁阻塞):在 API 中的介绍为:一个正在阻塞、等待一个监视器锁(锁对象)的线程处于这一状态。只有获得锁对象的线程才能有执行机会。
WAITING, // WAITING(无限等待):在 API 中介绍为:一个正在无限期等待另一个线程执行一个特别的(唤醒)动作的线程处于这一状态。
// 当前线程执行过程中遇到遇到 Object 类的 wait,Thread 类的join,LockSupport 类的 park 方法,并且在调用这些方法时,没有指定时间,那么当前线程会进入 WAITING 状态,直到被唤醒。
// 通过 Object 类的 wait 进入 WAITING 状态的要有 Object 的notify/notifyAll 唤醒;
// 通过 Condition 的 await 进入 WAITING 状态的要有Condition 的 signal 方法唤醒;
// 通过 LockSupport 类的 park 方法进入 WAITING 状态的要有LockSupport类的 unpark 方法唤醒
// 通过 Thread 类的 join 进入 WAITING 状态,只有调用join方法的线程对象结束才能让当前线程恢复
TIMED_WAITING, // TIMED_WAITING(计时等待):在 API 中的介绍为:一个正在限时等待另一个线程执行一个(唤醒)动作的线程处于这一状态。
// 当前线程执行过程中遇到 Thread 类的 sleep 或 join,Object 类的 wait,LockSupport 类的 park 方法,并且在调用这些方法时,设置了时间,那么当前线程会进入 TIMED_WAITING,直到时间到,或被中断
TERMINATED; // Teminated(被终止):表明此线程已经结束生命周期,终止运行。
}Thread类的特性?
- 每个线程都是通过某个特定Thread对象的run()方法来完成操作的,因此把run()方法体称为线程执行体。
- 通过该Thread对象的start()方法来启动这个线程,而非直接调用run()(如果使用Thread方法直接调用run方法,相当于main线程在执行该方法)
- 要想实现多线程,必须在主线程中创建新的线程对象
在学习线程的创建方式之前需要明白:下面的方式都只是创建线程的方式,本质上线程的创建方式只有一种,那就是Thread.start()
FixedThreadPool(固定大小线程池)
特点:
- 创建一个固定大小的线程池。
- 每次提交任务时,如果线程池中有空闲线程,则立即执行;如果没有空闲线程,则将任务放入队列中等待。
- 适用于负载较重、任务数量较多且持续有新任务到来的场景。
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(5);CachedThreadPool(缓存线程池)
线程池中线程数量不固定,可以根据需要自动创建新线程。当提交新任务时,如果没有空闲线程,则会创建新线程。
特点
- 创建一个根据需要创建新线程的线程池,但在之前构造的线程可用时将重用它们。
- 适用于执行大量短生命周期的任务,线程池会根据需要动态调整线程数量。
- 如果线程在60秒内未被使用,则会被终止并从缓存中移除。
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();SingleThreadExecutor(单线程池)
特点
- 创建一个只有一个线程的线程池。
- 保证所有任务按照提交顺序依次执行(FIFO)。
- 适用于需要串行执行任务的场景,确保任务不会并发执行
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();ScheduledThreadPool(定时线程池)
特点:
创建一个支持定时及周期性任务执行的线程池。
可以安排命令在给定的延迟后运行,或者定期执行(类似于Timer类,但更灵活且功能更强大)。
适用于需要定时或周期性执行任务的场景
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(4);
// 安排任务在指定延迟后执行
scheduledThreadPool.schedule(() -> System.out.println("Delayed Task"), 5, TimeUnit.SECONDS);
// 安排任务周期性执行
scheduledThreadPool.scheduleAtFixedRate(() -> System.out.println("Periodic Task"), 0, 2, TimeUnit.SECONDS);WorkStealingPool(工作窃取线程池)
使用多个工作队列减少竞争,适用于并行计算。线程池中的线程数量是Runtime.getRuntime().availableProcessors()的返回值。适用于需要大量并行任务的场景。
特点:
- 创建一个工作窃取线程池,使用 ForkJoinPool 实现。
- 线程池中的线程可以“窃取”其他线程的任务来执行,从而提高 CPU 利用率。
- 适用于处理大量细粒度的任务,特别适合并行计算任务。
ExecutorService workStealingPool = Executors.newWorkStealingPool();自定义线程池
除了上述预定义的线程池外,还可以使用 ThreadPoolExecutor 类来自定义线程池,以满足特定需求。例如,可以通过设置核心线程数、最大线程数、队列类型等参数来创建更灵活的线程池。
import java.util.concurrent.*;
public class CustomThreadPoolExample {
public static void main(String[] args) {
ThreadPoolExecutor customThreadPool = new ThreadPoolExecutor(
2, // 核心线程数
4, // 最大线程数
60L, TimeUnit.SECONDS, // 线程空闲时间
new LinkedBlockingQueue<Runnable>(), // 任务队列
new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略
);
// 提交任务
for (int i = 0; i < 10; i++) {
customThreadPool.execute(() -> System.out.println("Task " + Thread.currentThread().getName()));
}
// 关闭线程池
customThreadPool.shutdown();
}
}线程池的shutDown和shutDownNow的区别
ExecutorService接口中,shutdown()和shutdownNow()都是用于关闭线程池的方法
shutdown()
shutdown()方法会启动线程池的关闭过程。
它会停止接受新的任务提交,但会继续执行已经提交的任务(包括正在执行的和已提交但尚未开始执行的任务(即队列中的任务))。
调用shutdown()后,线程池会进入一个平滑的关闭过程,等待所有已提交的任务完成后才会完全终止
shutdownNow()
shutdownNow()方法会尝试停止所有正在执行的任务,并返回一个包含尚未开始执行的任务的列表。
它会立即停止接收新的任务,并试图中断正在执行的任务。
调用shutdownNow()后,线程池会尽快停止所有正在执行的任务(即它会尽力的中断任务),并返回尚未开始执行的任务列表。
需要注意的是,无法保证所有正在执行的任务都能被中断。
| 特性 | shutdown() | shutdownNow() |
|---|---|---|
| 停止接收新任务 | 是 | 是 |
| 等待现有任务完成 | 是(包括正在执行和排队的任务) | 否(尝试中断正在执行的任务) |
| 中断正在执行的任务 | 否 | 是(通过 interrupt() 方法)具体的中断效果取决于任务对中断信号的响应 |
| 返回未执行任务 | 否 | 是(返回尚未开始的任务列表) |
| 关闭速度 | 较慢(等待所有任务完成) | 较快(立即尝试关闭) |
多次调用shutDown或shutDownNow 会怎么样?
调用shutDown或shutDownNow后,再次调用它们不会有额外的效果,也不会抛出异常。